Understanding Distributed Systems (UDS) Notes
About#
These are my notes on Roberto Vitillo’s Understanding Distributed Systems. The book’s website can be found here.
Introduction#
A distributed system is one in which the failure of a computer you didn’t even know exited can render your own computer unusable.
— Leslie Lamport
- Motivations for building distributed systems include:
- High availability: resilience to single-node failures
- Large workloads that are too big to fit on a single node
- Performance requirements (e.g. high resolution & low latency for video streaming)
Table of Contents
Part I: Communication#
Chapter 2: Reliable Links#
- We can derive the maximum theoretical bandwidth of a network link by dividing the size of the congestion window by the round trip time:
Chapter 3: Secure Links#
- A secure communication link must make 3 guarantees:
- Encryption: asymmetric encryption and symmetric encryption (via TLS) are used to ensure that data can only be read by the communicating processes
- Authentication: the server and client should each authenticate that the other is who they claim to be, via certificates issued by certificate authorities (CAs)
- Integrity: TLS verifies the integrity of the data by calculating a message digest using a secure hash function
Chapter 4: Discovery#
- The Domain Name System (DNS) is a distributed, hierarchical, and eventually consistent key-value store
Chapter 5: APIs#
-
A textual format like JSON is self-describing and human-readable, at the expense of increased verbosity and parsing overhead
-
On the other hand, a binary format like Protocol Buffers is leaner and more performant, at the expense of human readability
-
Internal APIs are typically implemented with a high-performance RPC framework like gRPC
-
External APIs tend to be based on HTTP, often based on REST
Part II: Coordination#
Chapter 6: System Models#
- Fair-Loss Link Model: messages may be lost and duplicated, but if the sender keeps retransmitting a message, eventually it will be delivered to the destination
- Reliable Link Model: a message is delivered exactly once, without loss or duplication. A reliable link can be implemented on top of a fair-loss one by de-deduplicating messages at the receiver
- Authenticated Reliable Link Model: same assumptions as the reliable link but additionally assumes that the receiver can authenticate the sender
Chapter 7: Failure Detection#

- A process in a distributed system can proactively try to maintain a list of available processes using pings or heartbeats
- Ping: a periodic request that a process sends to another to check whether it’s still available
- Heartbeat: a message that a process periodically sends to another indicating that it is alive
Chapter 8: Time#
-
Physical Clocks
- The most common ones are based on vibrating quartz crystals, which are cheap but not very accurate
- Atomic clocks measure time based on quantum mechanical properties of atoms - they are more expensive than quartz clocks and accurate to 1 second in 3 million years
-
Logical Clocks
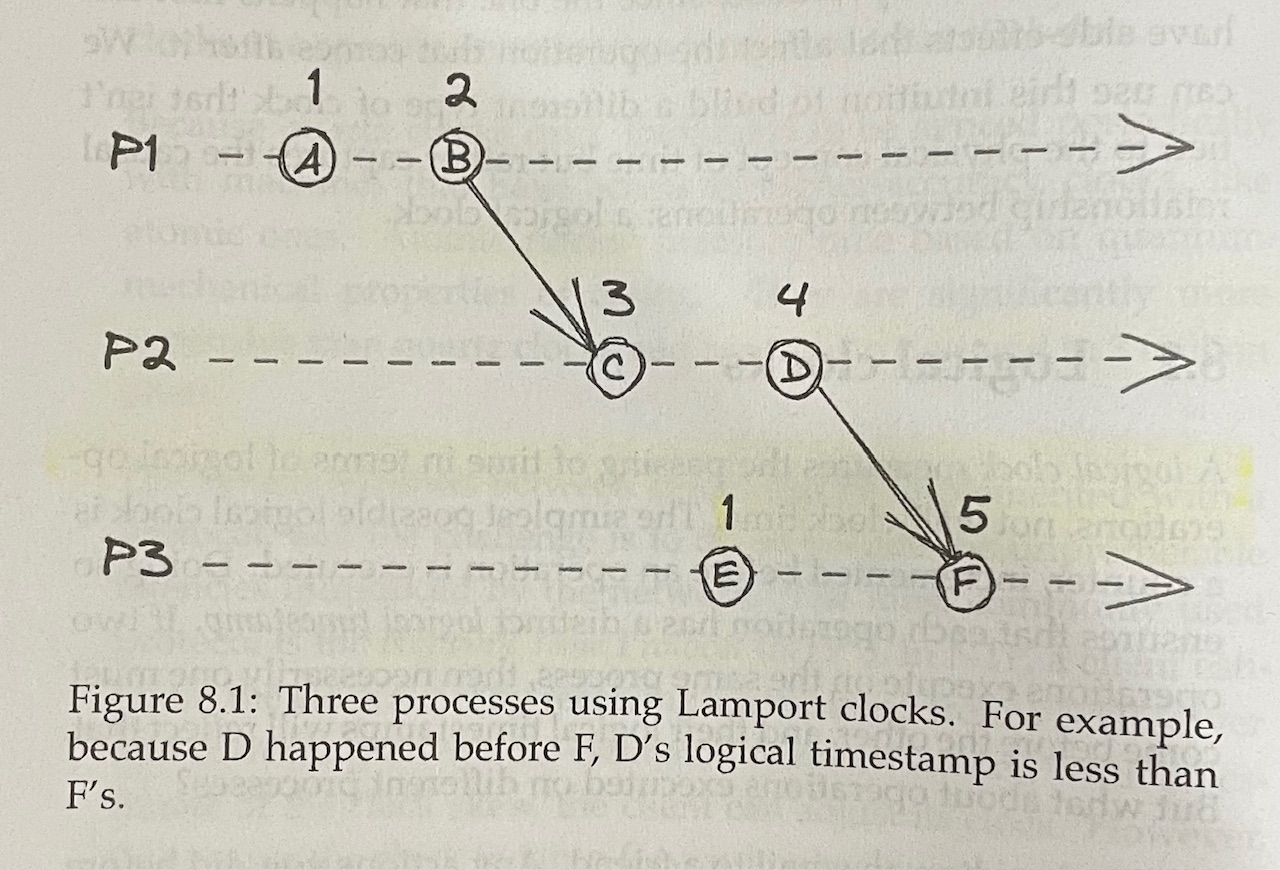
- A logical clock measures the passing of time in terms of logical operations, not wall-clock time
- A Lamport clock relies on each process in the system having a local counter that increments on operations, helping establish “happened before” relationships for operations across processes
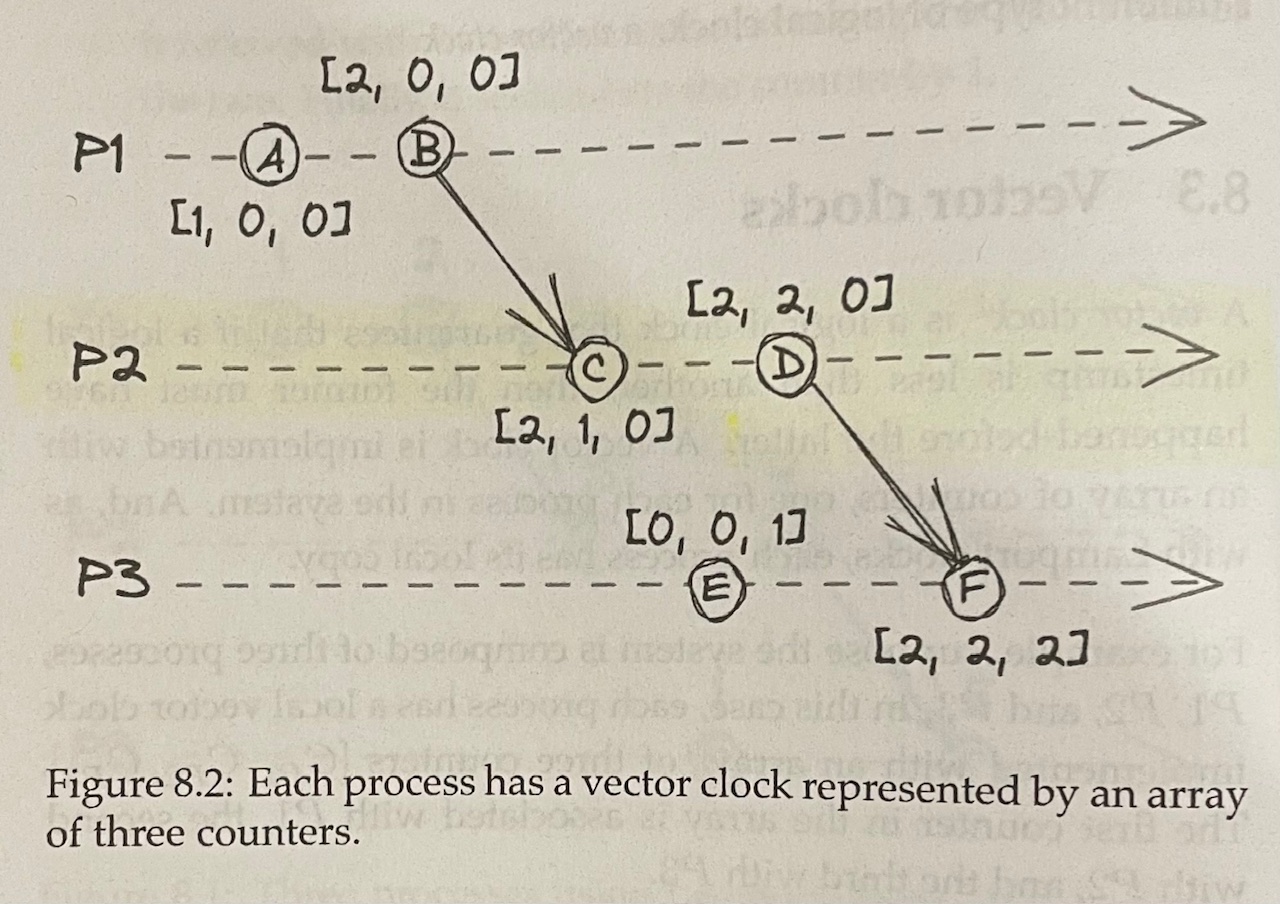
- Vector Clocks
- These are logical clocks that guarantee that if a logical timestamp is less than another, then the former must have happened-before the latter
Chapter 9: Leader Election#
-
A leader election algorithm needs to guarantee that there is at most one leader at any given time and that an election eventually completes, even in the presence of failures
-
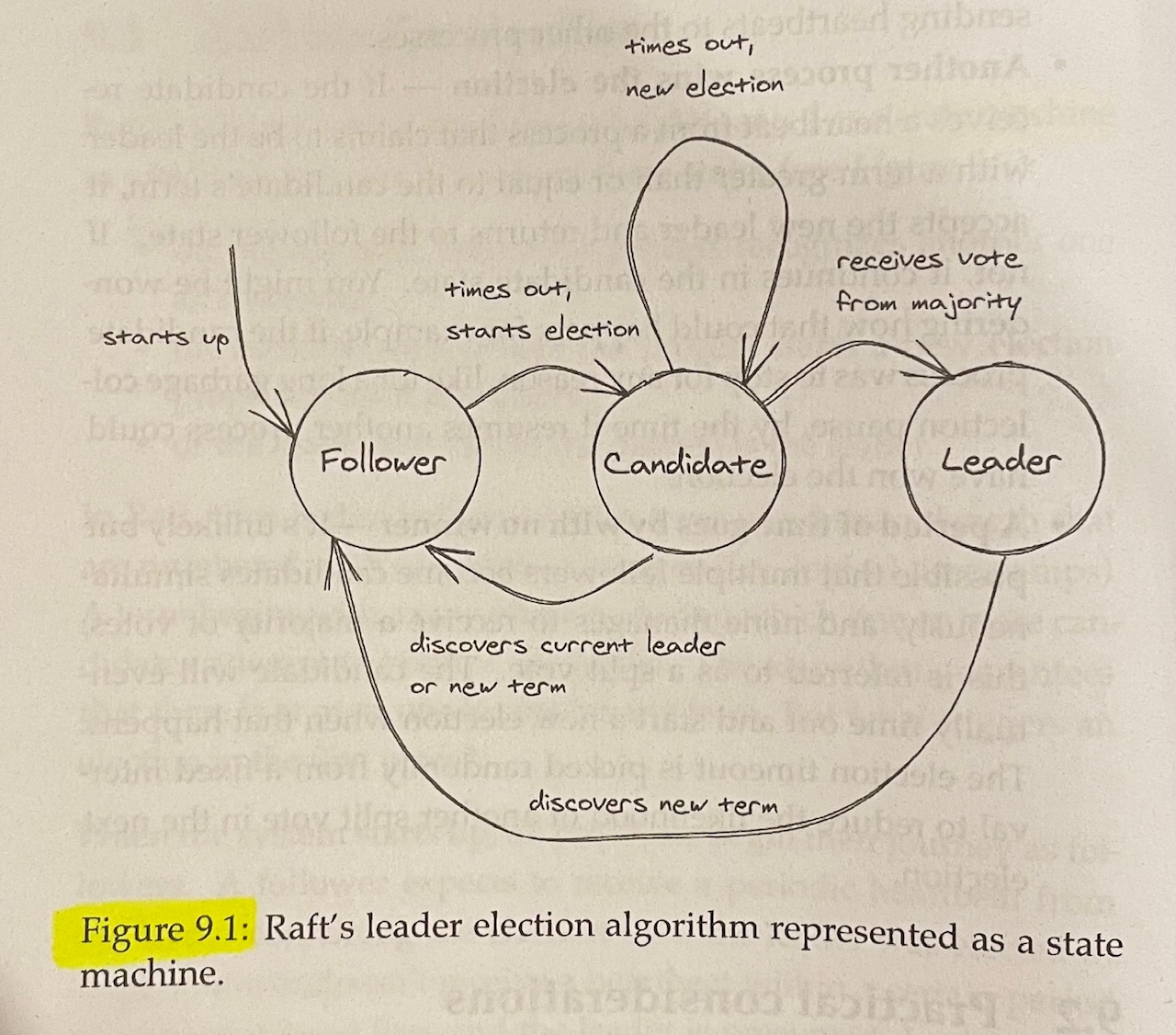
Raft’s leader election algorithm is implemented as a state machine, where any process is in one of three states:
- The follower state, where the process recognizes another one as the leader
- The candidate state, where the process starts a new election proposing itself as a leader
- The leader state, where the process is the leader
- Although having a leader can simplify the design of a system by eliminating concurrency, it can also become a scalability bottleneck if the number of operations it needs to perform increases to the point where it can no longer keep up
- The leader then becomes a single point of failure
Chapter 10: Replication#
State Machine Replication#
-
If a leader is the only process that can change the replicated state, then it should store the sequence of operations that alter the state into a local log, which it replicates to the followers so that the same operations can be performed in the same order
-
The leader waits to hear from a majority of followers (that the new log entry has been accepted) to consider an operation “committed”
Consensus#
- Consensus: a group of processes has to decide a value such that:
- Every non-faulty process eventually agrees on a value (Termination)
- The final decision of every non-faulty process is the same everywhere (Agreement)
- The value that has been agreed on has been proposed by a process (Integrity)
Consistency Models#
-
Since only the leader can make changes to the state, write operations must go through the leader
-
However, reads can be served by the leader, a follower, or a combination of leader and followers
-
Followers can lag behind the leader in terms of the system’s state, so there is a tradeoff between how consistent the observers’ views of the system are and the system’s performance and availability
-
Strong Consistency
- If clients send writes and reads exclusively to the leader, then we have linearizability, or strong consistency
-
Sequential Consistency
- A given client only ever queries the same follower
- Ensures that operations occur in the same order for all observers, but doesn’t provide any real-time guarantees about when an operation’s side effect becomes visible to them
-
Eventual Consistency
- Any client can query any follower, but this means that two followers could provide two different states at the same time
- The only guarantee provided is that eventually all followers will converge to the final state if writes to the system stop
-
The CAP Theorem
- “Strong consistency, availability, and partition tolerance”: pick two out of three
- In reality, the choice is between strong consistency and availability, since network faults are unavoidable
- Think of the relationship between consistency and availability as a spectrum –> the stronger the consistency guarantee is, the higher the latency of individual operations must be
- PACELC Theorem: in case of network partitioning (P), one has to choose between availability (A) and consistency (C), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C)
Chain Replication#
-
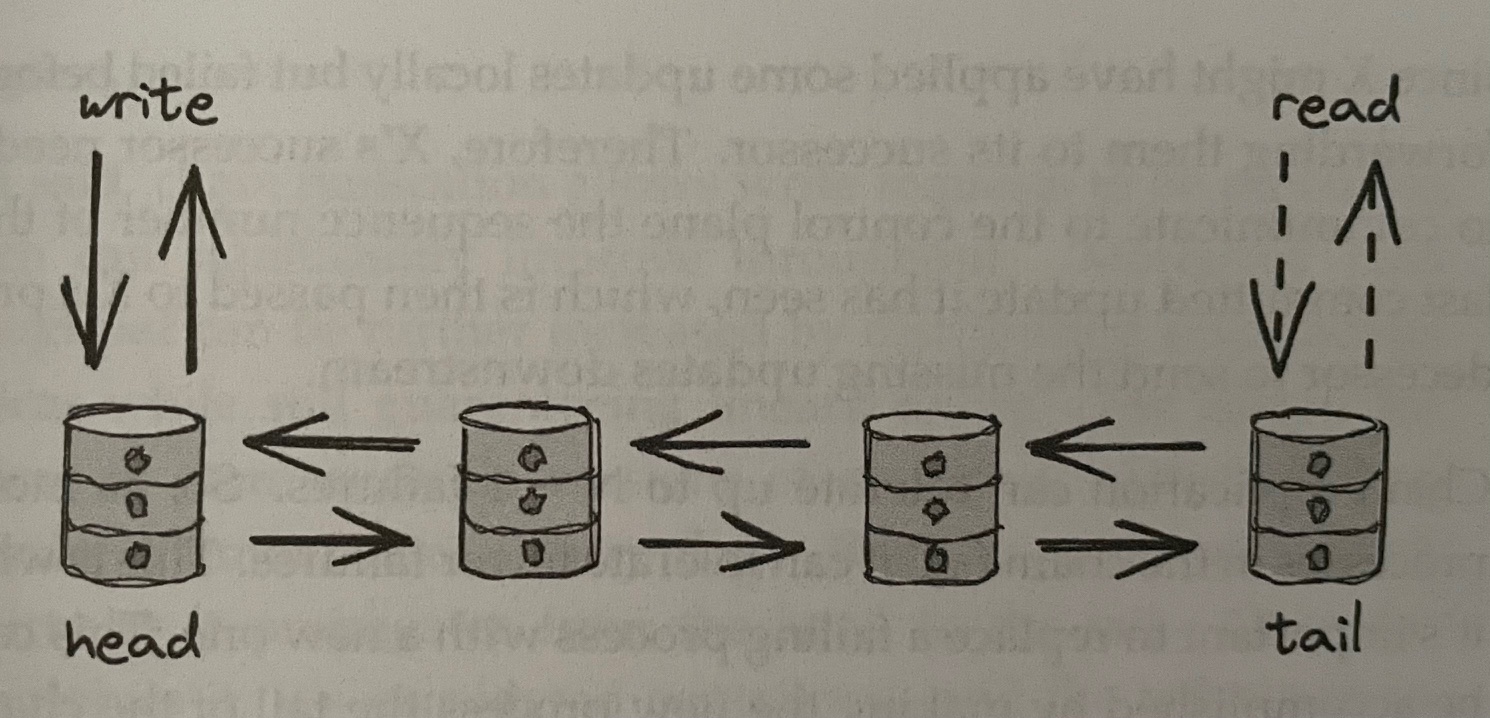
Instead of leader-based replication protocols like Raft, chain replication’s topology arranges processes in a chain
-
Clients send writes exclusively to the head, which updates its logical state and forwards the update down the chain to the next process
- When the tail receives an update, it sends an acknowledgement to its predecessor, which forwards the acknowledgement down the chain –> when the head receives the acknowledgement, it can reply to the client that the write succeeded
-
Client reads are served exclusively by the tail
-
Chain replication is simpler to understand and more performant than leader-based replication, but incurs higher write latency
Chapter 11: Coordination Avoidance#
- A fault-tolerant total order broadcast guarantees that every replica receives the same updates in the same order even in the presence of faults
Broadcast Protocols#
-
Best-Effort Broadcast: if the sender doesn’t crash, the message is delivered to all non-faulty processes in a group
-
Reliable Broadcast: the message is eventually delivered to all non-faulty processes in the group, even if the sender crashes mid-way
- One way to implement this is to have each process retransmit the message to the rest of the group the first time it is delivered (eager reliable broadcast) –> however, this requires sending the message $N^2$ times for a group of $N$ processes
- The number of messages can be reduced by retransmitting a message only to a random subset of processes (gossip broadcast protocol)
Conflict-Free Replicated Data Types#
- Strong Eventual Consistency: if we can define a deterministic outcome for any potential conflict (e.g. the write with the greatest timestamp always wins), there wouldn’t be any conflicts, by design
- Now, a client can send an update or query operation to any replica
Dynamo-Style Data Stores#
-
Dynamo is an eventually consistent and highly available key-value store
-
In Dynamo-style data stores, every replica can accept write and read requests
- Write: client sends request to all $N$ replicas in parallel but waits for an acknowledgement from just $W$ replicas (a write quorum)
- Read: client sends request to all $N$ replicas in parallel but waits for just $R$ replies (a read quorum)
- When $W + R > N$, at least one read will return the latest version
-
$W$ and $R$ can be tuned based on the availability / performance required
- For example, a read-heavy workload benefits from a smaller $R$, but this makes writes slower and less available (assuming $W + R > N$)
- If $W$ and $R$ are configured to be small ($W + R < N$), this boosts performance at the expense of consistency
-
To ensure that replicas converge, two anti-entropy mechanisms are used:
- Read Repair: when a client receives a reply with an older entry, the client can issue a write request with the latest entry to the out-of-sync replicas
- Replica Synchronization: a continuous background mechanism that runs on every replica and periodically communicates with others to identify and repair inconsistencies
The CALM Theorem#
-
CALM Theorem: a program has a consistent, coordination-free distributed implementation if and only if it is monotonic
- A program is monotonic if new inputs further refine the output and can’t take back any prior output
-
A program that computes the union of a set is monotonic - once an element (input) is added to the set (output), it can’t be removed
-
Variable assignment is a non-monotonic operation since it overwrites the variable’s prior value
- However, by combining the assignment operation with a logical clock, it’s possible to build a monotonic implementation (as seen earlier with LWW and MV registers)
Causal Consistency#
-
Causal Consistency is a weaker model than strong consistency but stronger than eventual consistency
- For many applications, it’s “consistent enough” and easier to work with than eventual consistency
- Provably the strongest consistency model that enables building systems that are also available and partition tolerant
-
In causal consistency, processes must agree on the order of causally related operations but can disagree on the order of unrelated ones
- With any two operations, either one happened-before the other, or they are concurrent and therefore can’t be ordered
- Strong consistency, on the other hand, imposes a global order that all processes agree with
Chapter 12: Transactions#
- Transactions provide the illusion that either all the operations within a group complete successfully or none of them do, as if the group were a single atomic operation
ACID#
-
In a traditional relational database, a transaction guarantees a set of properties, known as ACID
-
Atomicity guarantees that partial failures aren’t possible - either all operations in the transaction complete successfully, or none do
-
Consistency guarantees that the application-level invariants must always be true - a transaction can only transition a database from a correct state to another correct state
-
Isolation guarantees that a transaction appears to run in isolation as if no other transactions are executing, i.e. there are no race conditions between transactions
-
Durability guarantees that once the database commits the transaction, the changes are persisted on durable storage so that subsequent crashes don’t cause the changes to be lost
Isolation#
-
The easiest way to ensure that no transaction interferes with another is to run them all serially one after another (e.g. using a global lock)
- However, this is extremely inefficient - we want transactions to be able to run concurrently
-
However, a group of concurrently running transactions accessing the same data can run into race conditions:
- Dirty Write: a transaction overwrites the value written by another transaction that hasn’t committed yet
- Dirty Read: a transaction observes a write from a transaction that hasn’t completed yet
- Fuzzy Read: a transaction reads an object’s value twice but sees a different value in each read because another transaction updated the value between the two reads
- Phantom Read: a transaction reads a group of objects matching a specific condition, while another transaction concurrently adds, updates, or deletes objects matching the same condition
-
The stronger the isolation level is, the more protection it offers against race conditions, but the less performant it is
- Serializability is the only isolation level that isolates against all possible race conditions
-
Pessimistic concurrency control protocols (such as two-phase locking (2PL))use read and write locks to block other transactions from accessing an object
- With locks, it’s possible for two or more transactions to deadlock and get stuck
- More efficient for conflict-heavy workloads since they avoid wasting work
-
Optimistic concurrency control protocols execute transactions without blocking with the assumption that conflicts are rare and transactions are short-lived
- If post-transaction validation fails, the transaction is aborted and restarted
- Well-suited for read-heavy workloads that rarely perform writes or perform writes that only occasionally conflict with each other
Atomicity#
-
When a transaction is aborted, the data store needs to guarantee that all the changes the transaction performed are undone (rolled back)
- To guarantee atomicity, the data store records all changes to a write-ahead log (WAL) persisted on disk before applying them
- If a transaction is aborted or the data store crashes, the log contains enough information to redo changes to ensure atomicity and durability
-
However, this WAL-based recovery mechanism only guarantees atomicity within a single data store
- We want to extend atomicity to multiple transactions in a distributed system
-
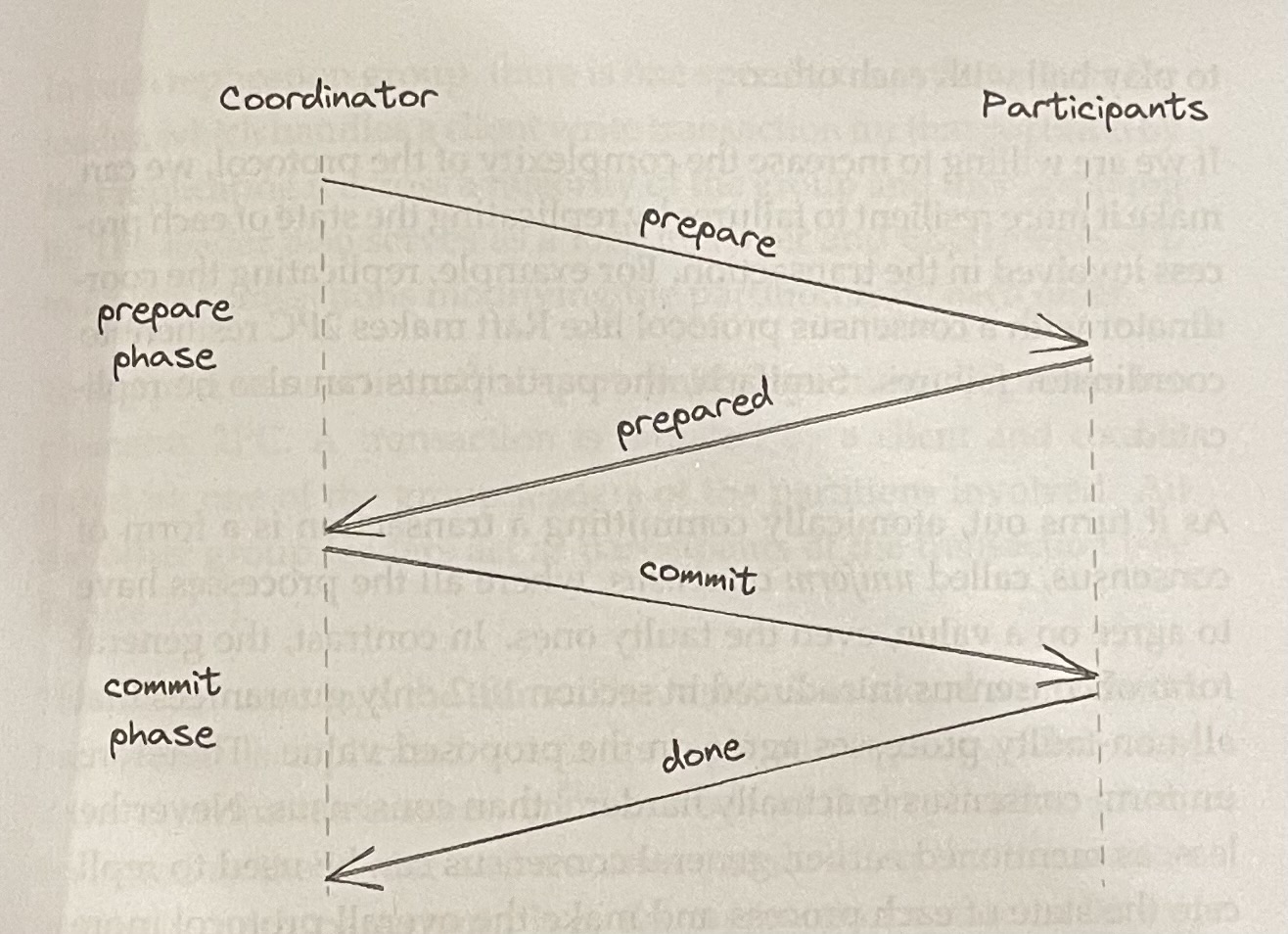
Two-phase commit (2PC) is used to implement atomic transaction commits across multiple processes
- Slow since it requires multiple round trips for a transaction to complete
- If either the coordinator or a participant fails, then all processes part of the transactions are blocked until the failing process comes back online
- Replicating the coordinator with a consensus protocol like Raft makes 2PC resilient to coordinator failures
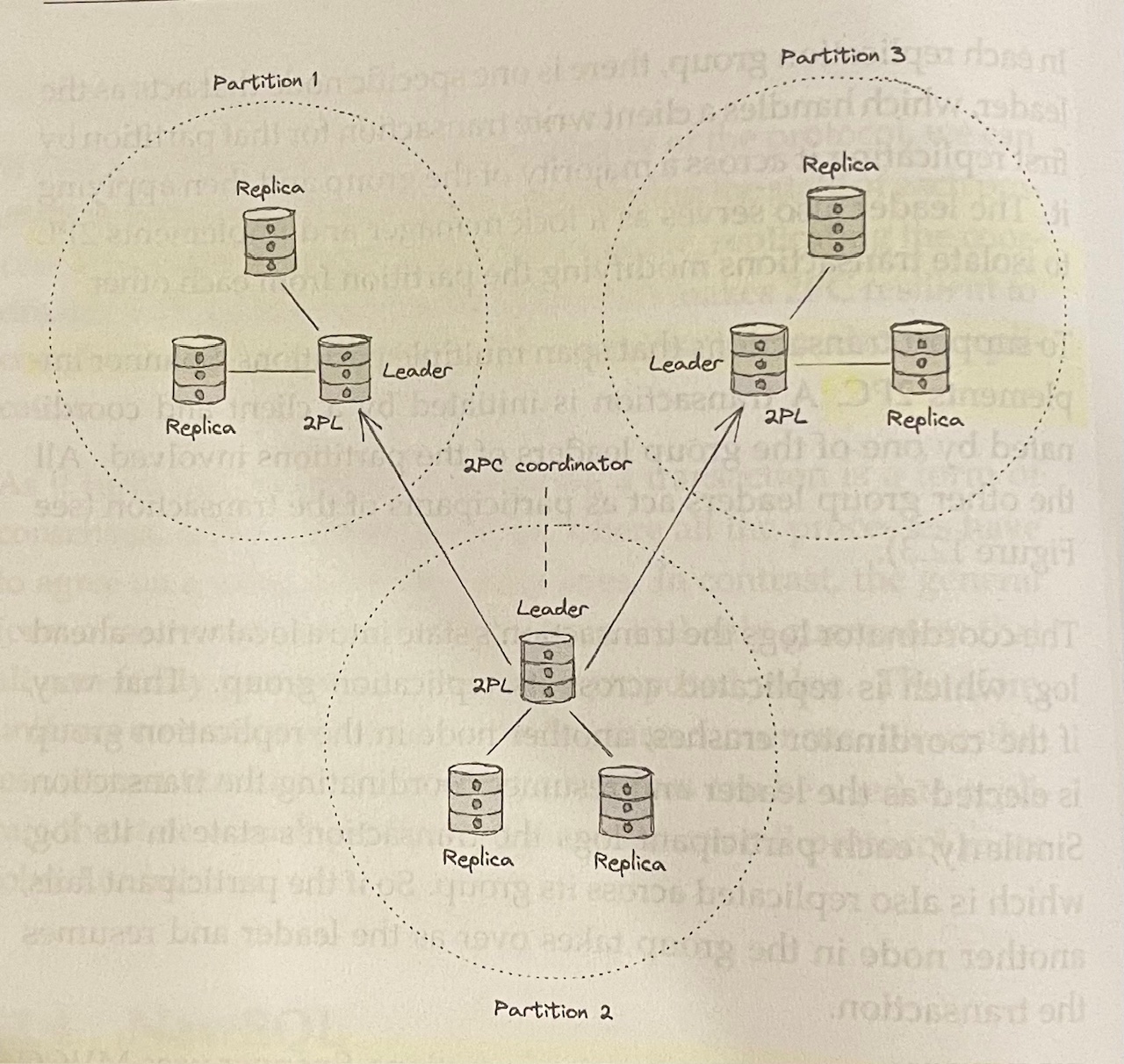
NewSQL#
- Google’s Spanner breaks data (key-value pairs) into partitions in order to scale
- Each partition is replicated across a group of nodes using a state machine replication protocol (Paxos)
- Each replication group has a node that acts as the leader, serving as the lock manager and implementing 2PL to isolate transactions
- To support transactions that span multiple partitions, Spanner implements 2PC
- To guarantee isolation between transactions, Spanner uses MVCC combined with 2PL
Chapter 13: Asynchronous Transactions#
Outbox Pattern#
- The outbox pattern is a common pattern to replicate the same data to different data stores
- We want the two data stores to be in sync, but we can accept some temporary inconsistencies, so eventual consistency is acceptable for our use case
- When some data is added, modified, or deleted, the first data store can send a persistent message to the other data store
- Because the relational database supports ACID transactions, the message is appended to the outbox table if and only if the local transaction commits and is not aborted
- The destination data store is guaranteed to process the message only once via an idempotency key
Sagas#
- A saga is a distributed transaction composed of a set of local transactions $T_1$, $T_2$, …, $T_n$, where $T_i$ has a corresponding compensating local transaction $C_i$ used to undo its changes
- The saga guarantees that either all local transactions succeed, or, in case of failure, the compensating local transactions undo the partial execution of the transaction altogether
Part III: Scalability#
-
Let’s say we have a simple CRUD web application called Cruder that we want to scale
- Single-page JavaScript application
- Communicates with an application server via a RESTful HTTP API
- The server uses local disk to store large files like images and videos
- The server uses a relational database to persist the application’s state
- The database and application server are hosted on the same machine (e.g. an EC2)
- The server’s public IP address is advertised by a managed DNS server (e.g. AWS Route 53)
-
The simplest way to increase capacity is to scale up the machine hosting the application:
- Provisioning more processors or cores –> more threads running simultaneously
- Provisioning more disks (RAID)
- Provisioning more NICs to increase network throughput
- Provisioning solid-state disks (SSD) to reduce random disk access latency
- Provisioning more memory to reduce page faults
-
The alternative is to scale out by distributing the application across multiple nodes
- This adds complexity, but makes the system much more scalable
- For example, we can move the database to a dedicated machine as a first step
Chapter 14: HTTP Caching#
-
Cruder’s application server handles both static resources (e.g. JavaScript or CSS files, images) and dynamic resources (e.g. JSON data containing users’ profiles)
- Static resources don’t change often, so they can be cached by the browser to reduce server load
- The “Cache-Control” HTTP header is used by servers to indicate to clients how long to cache resources for (TTL)
-
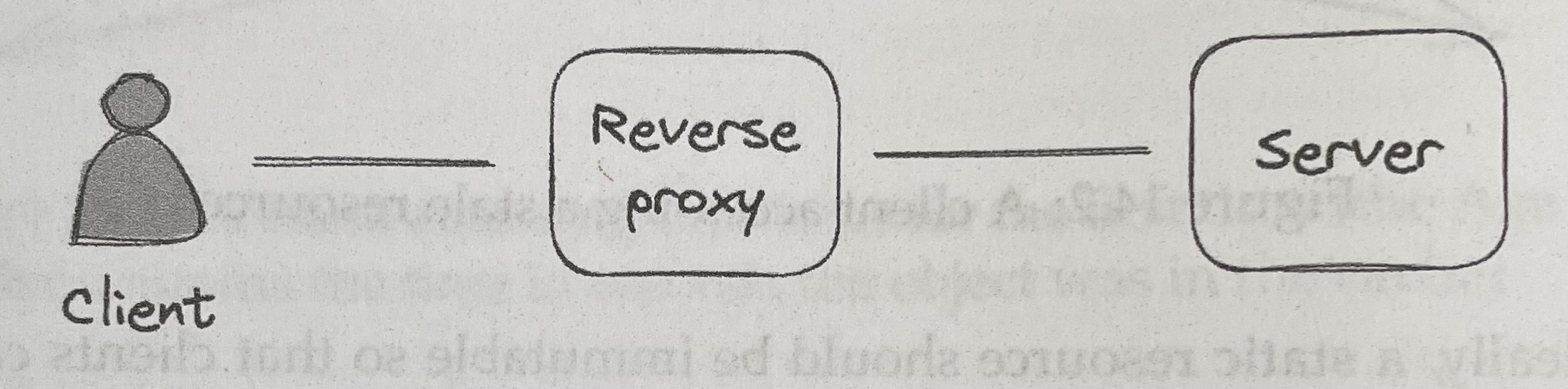
A reverse proxy is a server-side proxy that intercepts all communications with clients
- A common use case for reverse proxies is to cache static resources returned by the server, helping decrease server load
- Because a reverse proxy is a middleman, it can be used for much more than just caching, e.g. authentication of requests, compressing server responses, rate-limiting from specific IPs or users, load balancing across multiple servers
- nginx is a commonly-used reverse proxy
Chapter 15: Content Delivery Networks#
-
A content delivery network (CDN) is an overlay network of geographically distributed caching servers (reverse proxies)
- When a CDN server receives a request, it either returns the requested resource from its local cache or fetches it from the origin server (our application server)
- AWS CloudFront and Akamai are commonly-used CDNs
-
CDN clusters are placed strategically so they are geographically closer to clients
- Global DNS Load Balancing is used to infer the location of a client from its IP and determine a list of the geographically closest clusters, taking into account the network congestion and the clusters’ health
- CDN servers are also placed at internet exchange points, where ISPs connect to each other
Chapter 16: Partitioning#
- When’s an application’s data becomes too large to fit on a single machine, it needs to be split into partitions, or shards, that are small enough to fit into individual nodes
- A gateway service (i.e. a reverse proxy) is often in charge of routing a request to the node(s) responsible for it
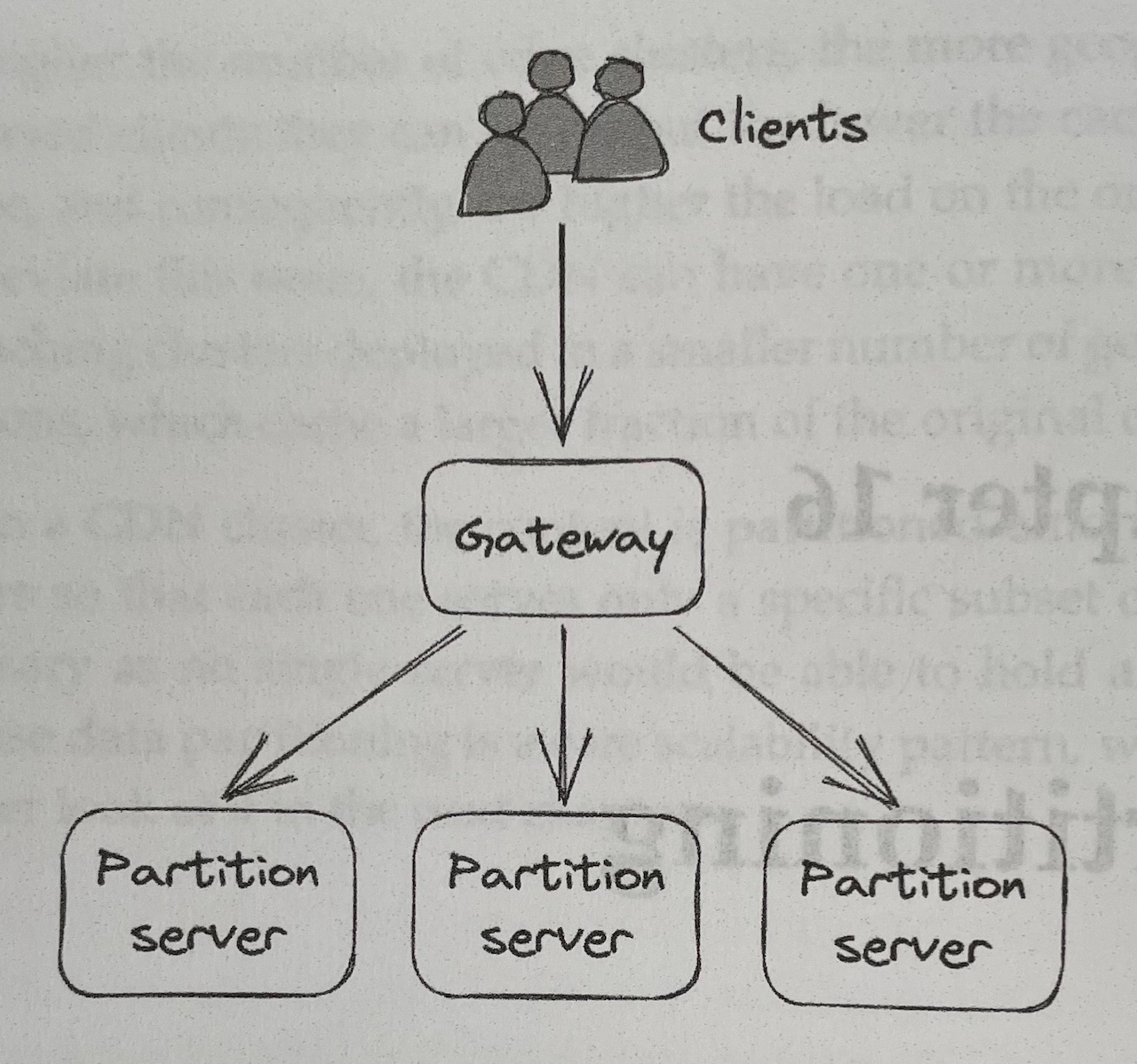
- Partitioning introduces a fair bit of complexity:
- Requests need to be routed to the right nodes
- Data sometimes need to be pulled from multiple partitions and aggregated (e.g. “group by”)
- Transactions are required to atomically update data that spans multiple partitions, limiting scalability
- Some partitions could be accessed much more frequently than others
- Adding or removing partitions becomes challenging, since it requires moving data across nodes
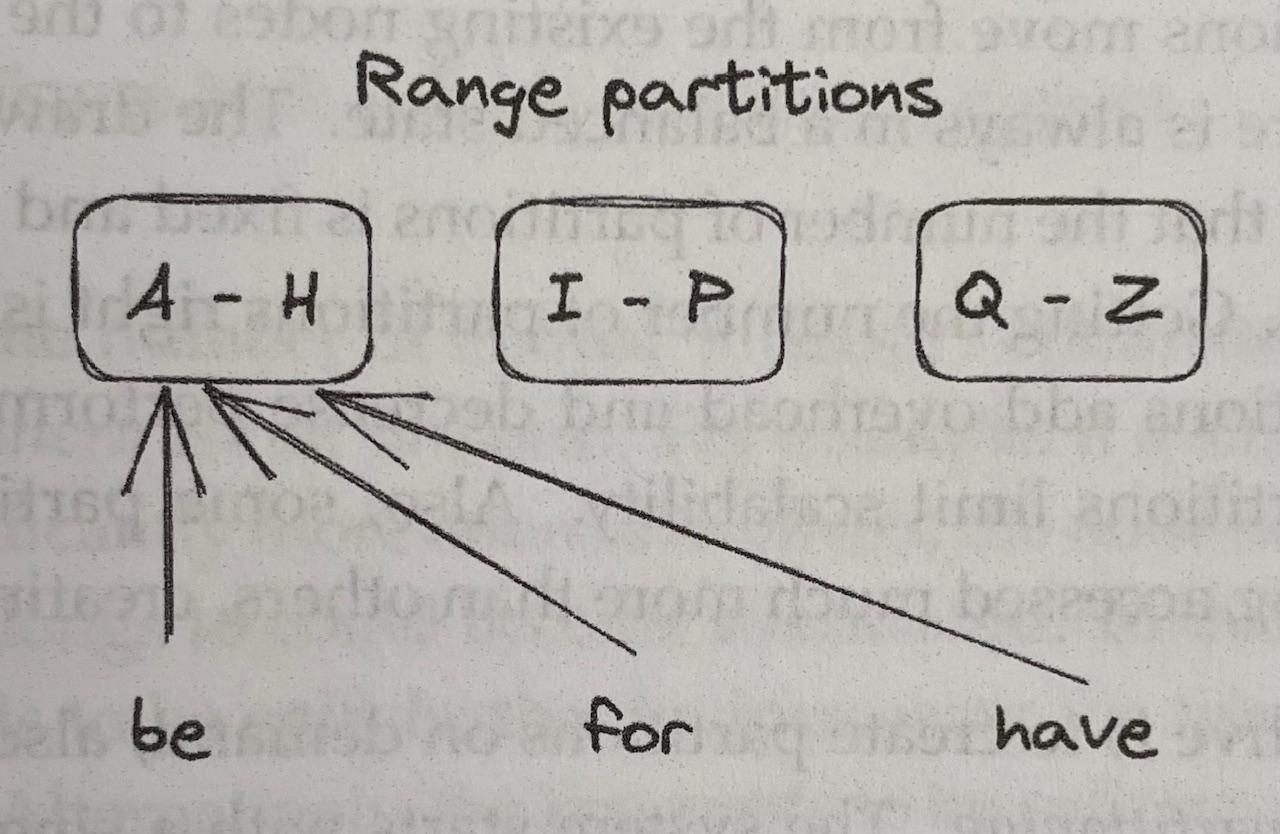
Range Partitioning#
-
Range Partitioning splits the data by key range into lexicographically sorted partitions
- Picking the partition boundaries is challenging since we want the key range to be roughly evenly distributed across the partitions
- Some access patterns can lead to hotspots –> for example, if the data is range partitioned by date, all requests for the current day will be served by a single node
-
When we want to increase or decrease the number of nodes, we need to rebalance the data
- The amount of data transferred when rebalancing partitions should be minimized
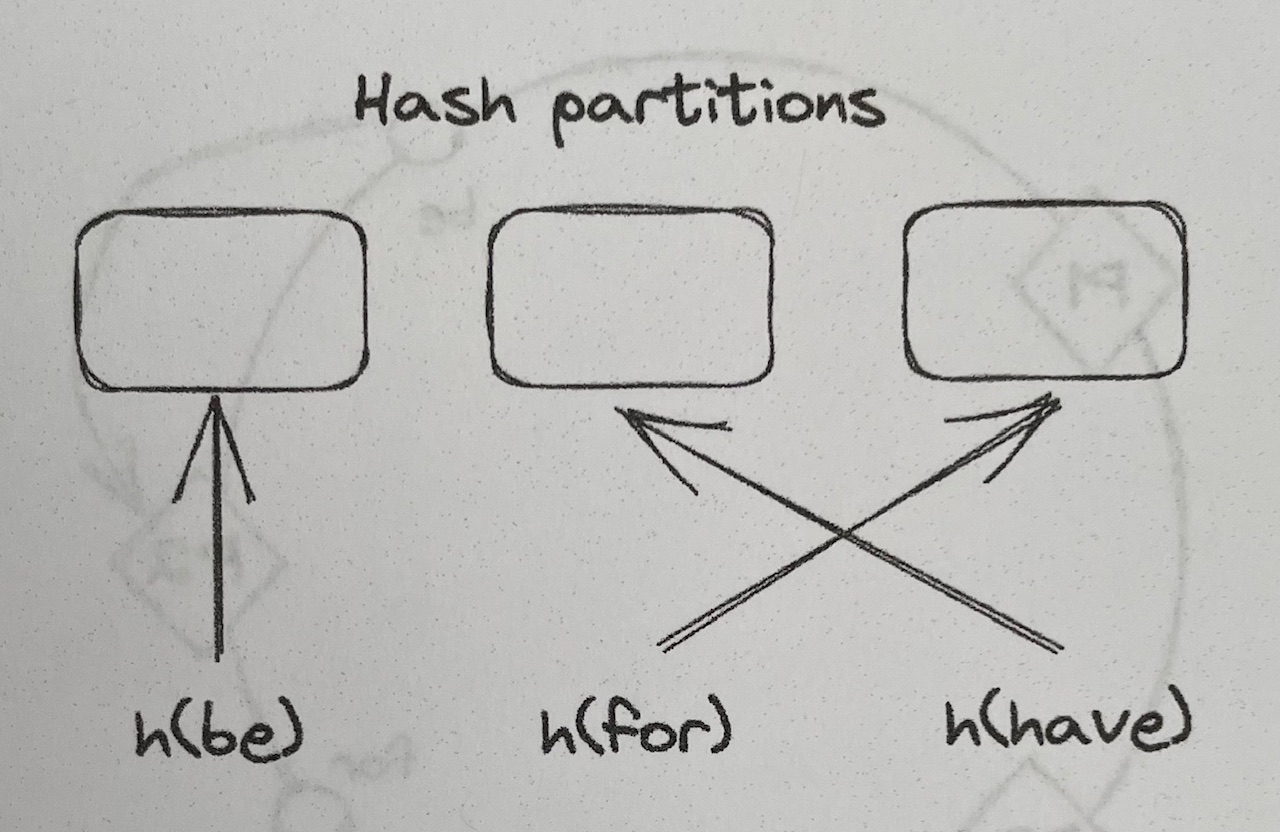
Hash Partitioning#
- Hash Partitioning uses a hash function that maps a key (string) to a hash within a certain range (e.g. between $0$ and $2^{64} - 1$)
- This guarantees that the keys’ hashes are distributed uniformly across the range
- Hashes can be assigned to each partition via $hash(key)$ $mod$ $N$, where $N$ is the number of partitions
- Assigning hashes to partitions via the modulo operator can be problematic when new partitions are added, since most keys have to be moved (or shuffled), which is expensive
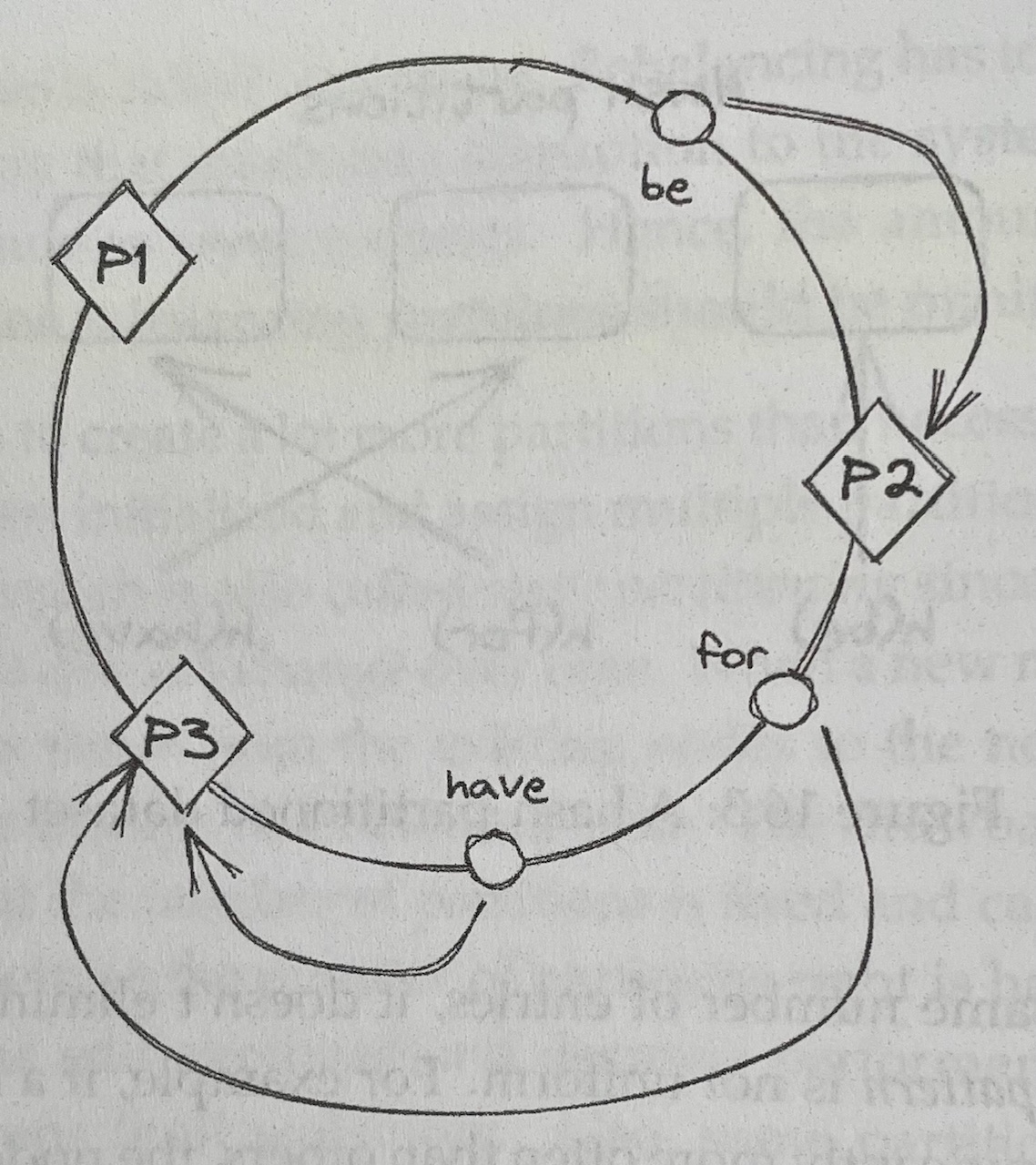
- With Consistent Hashing, a hash function randomly maps the partition identifiers and keys onto a circle, and each key is assigned to the closest partition that appears on the circle in clockwise order
- When a new partition is added, only the keys that now map to it on the circle need to be reassigned
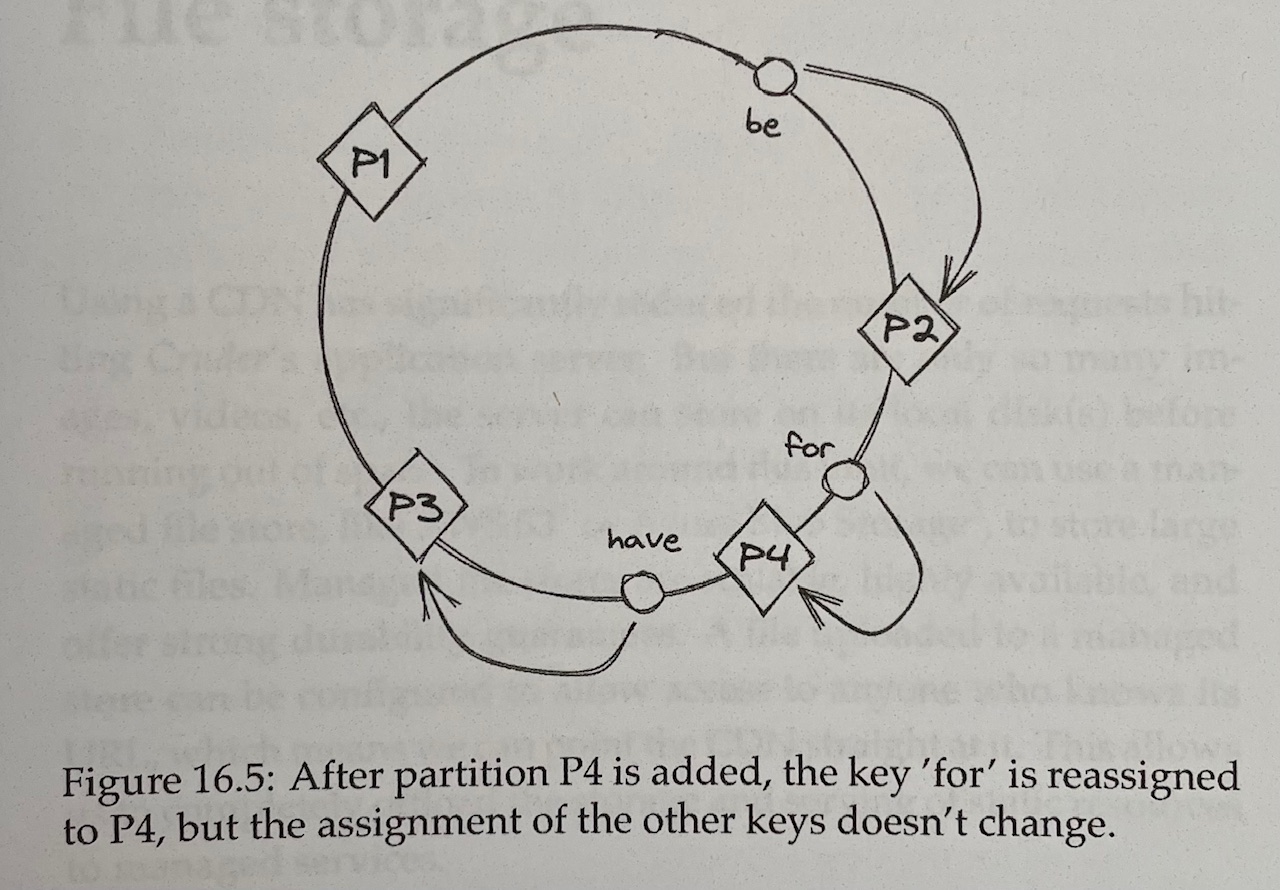
- The main drawback of hash partitioning compared to range partitioning is that the sort order over the partitions is lost, which is required to efficiently scan all the data in order
- However, the data within an individual partition can still be sorted based on a secondary key
Chapter 17: File Storage#
- We can use a managed file store, like AWS S3 or Azure Blob Storage, to store large static files
- A file in a managed file store can be configured to allow access to anyone who knows its URL, which means we can point the CDN straight at it
Chapter 18: Network Load Balancing#
- We can further scale Cruder by creating multiple application servers, each running on a different machine, and having a load balancer distribute requests to them
- The number of servers behind the load balancer can increase or decrease without clients becoming aware
- A load balancer can detect faulty servers and take them out of the pool
- By increasing the number of servers linearly, we increase the availability exponentially (the probability that all our servers fail decreases rapidly)
Features Offered by Load Balancers#
Load Balancing#
-
Routing of requests can rely on various algorithms:
- Round-robin
- Consistent hashing
- Balancing based on the servers’ current loads
- To do this, the load balancer could periodically sample a dedicated load endpoint exposed by each server indicating the CPU usage on that server
- Repeatedly querying the servers might be expensive, so the load balancer might cache the responses for some time
- Using cached metrics to distribute requests can result in strange behavior, e.g. oscillating between being very busy and not being busy at all
-
As it turns out, randomly distributing requests to servers without accounting for their load achieves a better load distribution
- You can combine distribution by load and random distribution: randomly pick two servers from the pool and route the request to the least-loaded one of the two (this works very well in practice)
Service Discovery#
-
A fault-tolerant coordination service, like etcd or Zookeeper, can be used to manage the pool of servers it can route requests to
- When a new server comes online, it registers itself to the coordination service with a TTL
- When the server unregisters itself, or the TTL expires because it hasn’t renewed its registration, the server is removed from the pool
-
Adding and removing servers dynamically from the load balancer’s pool is a key functionality for autoscaling, i.e. the ability to spin up and tear down servers based on load
Health Checks#
-
A load balancer uses health checks to detect when a server can no longer serve requests and needs to be temporarily removed from the pool
- A passive health check is performed by the load balancer as it routes incoming requests to the servers downstream
- An active health check requires the downstream servers to expose a dedicated health endpoint that the load balancer can query periodically to infer the server’s health
-
Thanks to health checks, the application behind the load balancer can be updated to a new version without any downtime
- During the update, a rolling number of servers report themselves as unavailable so that the load balancer stops sending requests to them
- In-flight requests are allowed to complete (drain) before the servers are restarted with the new version
-
More generally, we can use this mechanism to restart a server (e.g. if it’s in a degraded state) without causing harm, since our system is self-healing
DNS Load Balancing#
-
If we have a few servers we want to load-balance requests over, we can add those servers’ public IP addresses to the application’s DNS record and have the clients pick one (round-robin DNS) when resolving the DNS address
- This approach isn’t resilient to failures, since the DNS server will continue serving an IP address even if that server goes down
-
In practice, DNS is used to load-balance traffic to different data centers located in different regions (global DNS load balancing, which was discussed above in relation to CDNs)
Transport Layer Load Balancing#
-
A network load balancer (aka L4 load balancer) operates at the TCP level of the network stack, through which all traffic between clients and servers flows
- Has one or more physical network interface cards mapped to one or more virtual IP (VIP) addresses
- A VIP, in turn, is associated with a pool of servers
- Clients only see the VIP exposed by the load balancer and have no visibility of the individual servers associated with it
-
When a client creates a new TCP connection with a load balancer’s VIP, the load balancer picks a server from the pool to serve the connection
- All traffic going both ways is forwarded by the load balancer between client and server
-
A network load balancer just shuffles bytes around without knowing what they actually mean, so it can’t support features that require higher-level network protocols (like terminating TLS connections)
- A load balancer that operates at a higher level of the network stack is required to support these advanced use cases
Application Layer Load Balancing#
-
An application layer load balancer (aka L7 load balancer) is an HTTP reverse proxy that distributes requests over a pool of servers
-
The load balancer can do smart things with traffic, like:
- Rate-limit requests based on HTTP headers
- Terminate TLS connections
- Force HTTP requests belonging to the same logical session to be routed to the same backend server
-
A L7 load balancer can be used as the backend of a L4 load balancer that load-balances requests received from the internet
- L7 load balancers have more capabilities but also less throughput than L4 load balancers
Chapter 19: Data Storage#
Replication#
-
We can increase the read capacity of the database by creating more replicas
-
The most common way of doing this is with a leader-follower topology
- Writes are sent exclusively to the leader, and followers stream log entries from the leader
- Followers are read-only and can be placed behind a load balancer, increasing capacity and availability
-
If replication is fully asynchronous, the leader receives a write, broadcasts it to the followers, and immediately sends a response back to the client without waiting for followers to acknowledge
- Minimizes response time for the client
- Not fault-tolerant: the leader could crash right after acknowledging a write and before broadcasting it to the followers, resulting in data loss
-
If replication is fully synchronous, the leader waits for the write to be acknowledged by the followers before returning a response to the client
- Fault-tolerant: minimizes probability of data loss
- Performance cost: a single slow replica increases the response time of every request + if any replica is unreachable, the data store becomes unavailable + not a scalable approach
-
In practice, relational databases often support a combination of synchronous and asynchronous replication
- For example, we could have some synchronous followers and some asynchronous followers (where the former would server as up-to-date backups of the leader)
-
Issues with replication
- Replication only helps to scale out reads, not writes
- The entire database needs to fit on a single machine
-
We can overcome these limitations with partitioning
Partitioning#
-
Partitioning allows us to scale out a database for both reads and writes
-
Challenges with implementing partitioning
- We need to decide how to rebalance data when a partition becomes too hot or too big
- Queries that span multiple partitions need to be split into sub-queries and their responses have the be combined (e.g. aggregations or joins)
- To support atomic transactions across partitions, we need to implement a distributed transaction protocol, like 2PC
-
The fundamental problem with relational databases is that they have been designed under the assumption that they fit on a single beefy machine
- Therefore, they support features that are hard to scale, e.g. ACID transactions and joins
NoSQL#
-
While relational databases support stronger consistency models such as strict serializability, NoSQL stores embrace relaxed consistency models such as eventual and causal consistency to support high availability
-
NoSQL stores generally don’t provide joins and rely on the data, often represented as key-value pairs or documents (e.g. JSON), to be unnormalized
-
The primary key can consist of either a single attribute, the partition key, or of two attributes, the partition key and the sort key
- The partition key dictates how the data is partitioned and distributed across nodes
- The sort key defines how the data is sorted within a partition, allowing for efficient range queries
-
DynamoDB creates three replicas for each partition and uses state machine replication to keep them in sync
- Writes are routed to the leader, and an acknowledgment is sent to the client when two out of three replicas have received the write
- Reads can either be eventually consistent (pick any replica) or strongly consistent (query the leader)
-
NoSQL stores are tightly coupled to the access patterns, since we need to structure the tables in such a way that queries don’t require any joins
- NoSQL stores are generally less flexible than relational databases for this reason
Chapter 20: Caching#
-
A cache is a high-speed storage layer that temporarily buffers responses from an origin, like a data store, so that future requests can be served directly from it
- For a cache to be cost-effective, the proportion of requests that can be served directly from it (the cache hit ratio) should be high
-
Because a cache has a limited capacity, one or more entries need to be evicted to make room for new ones when its capacity is reached
- One commonly used policy is to evict the Least Recently Used (LRU) entry
-
A cache should also have an expiration policy that dictates when an object should be evicted, e.g. a TTL
- The longer the expiration time, the higher the hit ratio, but the higher the likelihood of serving stale and inconsistent data
Local Cache#
-
The simplest way to implement a cache is to co-locate it with the client: a simple in-memory hash table or an embeddable key-value store
- Because each client cache is independent of the others, the same objects are duplicated across caches, wasting resources
- Consistency issues may arise, since two clients might see different versions of the same object
-
As the number of clients grows, the number of requests to the origin increases
- When clients restart, or new ones come online, their caches need to be populated from scratch –> this can cause a thundering herd effect where the downstream origin is hit with a spike or requests
External Cache#
-
An external cache is a service shared across clients dedicated to caching objects, typically in memory (e.g. Redis or Memcached)
- Unlike a local cache, an external cache can increase its throughput and size using replication and partitioning
- The cache will eventually need to be scaled out if the load increases
- The latency to access an external cache is higher since a network call is required
-
If the external cache goes down, clients should not necessarily bypass the cache and directly hit the origin temporarily, since the origin might not be prepared to withstand a sudden surge of traffic
- Clients could use a local cache as a defense against the external cache becoming unavailable
- Caching is an optimization, and the system needs to survive without it at the cost of being slower
Chapter 21: Microservices#
-
As codebases grow larger, the components will likely become increasingly coupled, becoming complex enough that nobody fully understands all of it and implementing new features or fixing bugs becomes more time-consuming
- Also, a change to a single component might require the entire application to be rebuilt and deployed
-
A monolithic application can be functionally decomposed into a set of independently deployable services that communicate via APIs
- Each service in the microservice architecture can have its own responsible team, tech stack, independent data model, data stores, etc.
-
It’s generally best to start with a monolith and decompose it only when there is a good reason to do so
Caveats of the Microservice Architecture#
-
Tech Stack: more difficult for engineers to move from one team to another due to lower standardization across services
-
Communication: remote calls are expensive and introduce non-determinism
-
Coupling: ideally, microservices should be loosely coupled
- However, microservices can be poorly implemented in such a way that they end up coupled, bringing the downsides of a monolith
-
Resource Provisioning: it should be simple to provision new machines, data stores, and other commodity resources
- You don’t want every team to come up with their own way of doing it
-
Testing: testing the integration of microservices is difficult
-
Operations: there should be a common way of continuously delivering and deploying new builds safely to production
-
Eventual Consistency: the data model no longer resides in a single data store, so the microservice architecture typically requires embracing eventual consistency
API Gateway#
- With a layer of indirection, we can hide the internal APIs behind a public one that acts as a facade, or proxy, for the internal services
- The service that exposes the public API is called the API gateway (a reverse proxy)
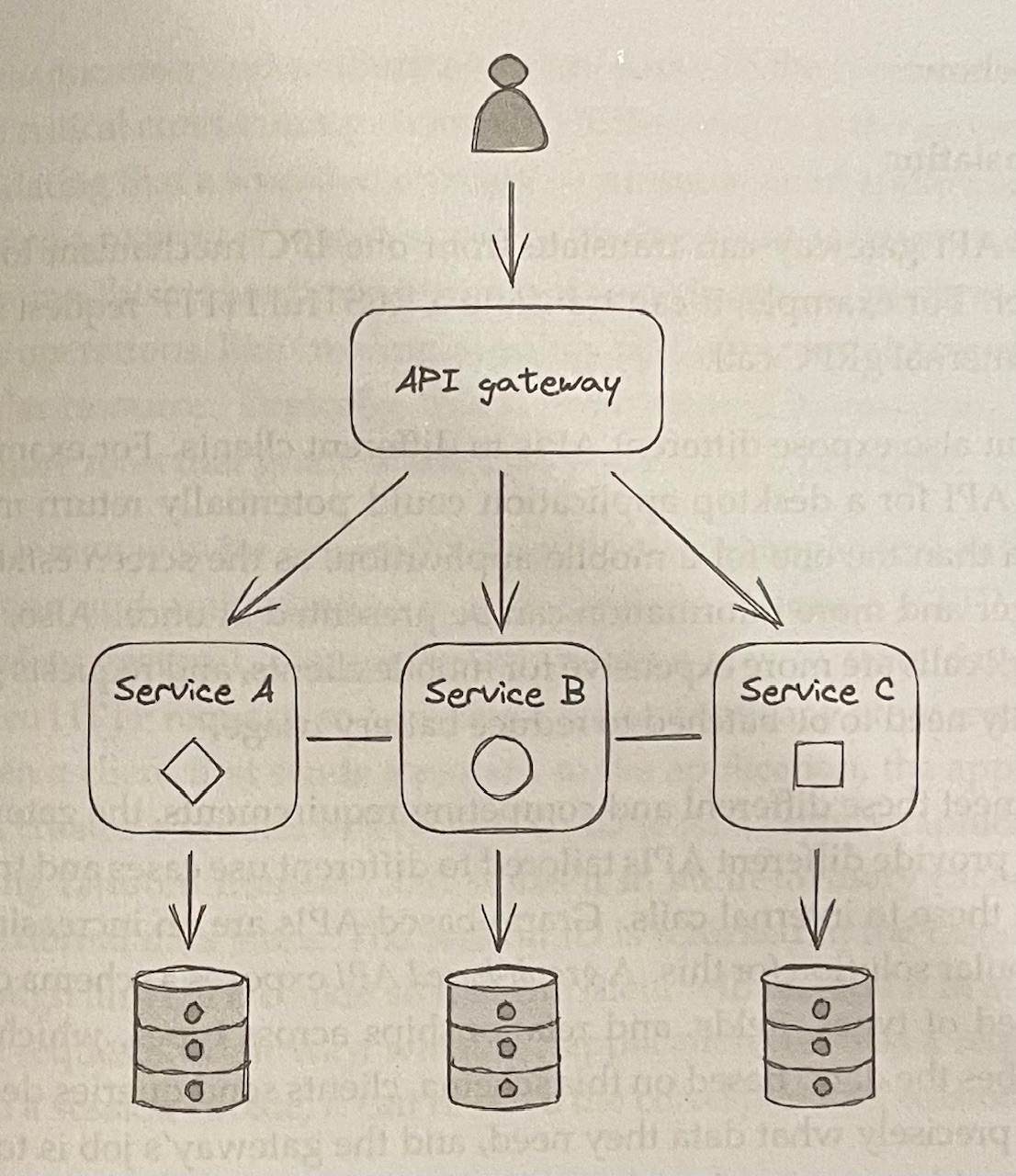
-
Responsibilities of the API gateway
- Routing: routing inbound requests to internal services
- Composition: offer a higher-level API that queries multiple services and composes their responses (stitching data together from multiple stores)
- Translation: translating from one IPC mechanism to another (e.g. translating a RESTful HTTP request into an internal gRPC call)
- Graph-based APIs such as GraphQL can be used to write queries declaring precisely what data is needed
-
An API gateway can also perform authentication (validating a human or an application issuing a request) and authorization (granting the authenticated principal permissions to perform specific operations)
- A common way for a monolithic application to implement authentication and authorization is with sessions (stored in an in-memory cache or external data store and the session ID is returned in the response through an HTTP cookie so the client will include it in all future requests)
- In a microservice architecture, a common approach is to have the API gateway authenticate external requests, since that’s their point of entry, but leave authorizing requests to individual services
-
A popular standard for transparent tokens that embed the principal’s information within the token itself is the JSON Web Token (JWT)
- A JWT is a JSON payload that contains an expiration date, the principal’s identity and roles, and other metadata
- The payload is signed with a certificate trusted by the internal services
-
Another common mechanism for authentication is the use of API keys
- An API key is a custom key that allows the API gateway to identify the principal making a request and limit what they can do
Chapter 22: Control Planes and Data Planes#
-
We can split our API gateway into a data plane service that services external requests directed towards our internal services and a control plane service that manages the gateway’s metadata and configuration
-
A data plane includes any functionality on the critical path that needs to run for each client request
- Therefore, it must be highly available, fast, and scale with the number of requests
-
A control plane is not on the critical path and has less strict scaling requirements
- Its main job is to help the data plane to its work by managing metadata or configuration and coordinating complex and infrequent operations
- It generally needs to offer a consistent view of its state to the data plane, so its favors consistency over availability
-
The data plane needs to be designed to withstand control plane failures for the separation to be robust
- if the data plane stops serving requests when the control plane becomes unavailable, we say the former has a hard dependency on the latter
- When we have a chain of components that depend on each other, the theoretical availability of the system is the product of the availabilities of the components
Scale Imbalance#
-
Generally, data planes and control planes tend to have very different scale requirements
- This creates a risk as the data plane can overload the control plane
-
One solution is to use a scalable file store, like S3, as a buffer between the control plane and the data plane
- The control plane periodically dumps its entire state to the file store, and the data plane reads the state periodically from it
- The intermediate data store protects the control plane by absorbing the load generated by the data plane
- However, this results in higher latencies and weaker consistency guarantees
-
Alternatively, we can have the control plane push the configuration directly to the data plane whenever it changes, rather than being at the mercy of periodic queries from the data plane
- This should reduce the propagation time when the state is very large
Control Theory#
-
In control theory, the goal is to create a controller that monitors a dynamic system, compares its state to the desired one, and applies a corrective action to drive the system closer to it while minimizing any instabilities on the way
-
All three components (monitor, compare, action) are critical to form a closed feedback loop
Chapter 23: Messaging#
-
Messaging is a form of indirect communication in which a producer writes a message to a channel – or message broker – that delivers the message to a consumer on the other end
- The message channel acts as a temporary buffer for the receiver
- Messages are deleted from the channel only when they are successfully processed by the consumer, so the request will eventually be picked up again and retried if the consumer fails at first
-
Decoupling the producer from the consumer provides several benefits:
- The producer can send requests to the consumer even if the consumer is temporarily unavailable, without fear of losing messages
- Requests can be load-balanced across a pool of consumer instances, making it easier to scale out
- The consumer can read from the channel at its own pace, preventing it from getting overloaded
- Most messaging brokers allow clients to fetch up to $N$ messages with a single read request, improving the application’s throughput
-
In a point-to-point channel, the message is delivered to exactly one consumer instance
-
In a publish-subscribe channel, each consumer instance receives a copy of the message
Common Messaging Communication Styles#
-
One-Way Messaging: the producer writes a message to a point-to-point channel with the expectation that a consumer will eventually read and process it
-
Request-Response Messaging: the consumer reads messages from a point-to-point request channel, while very producer has its dedicated response channel
-
Broadcast Messaging: the producer writes a message to a publish-subscribe channel to broadcast it to all consumer instances
Guarantees#
-
A message channel is implemented by a messaging service, or broker, like AWS SQS or Kafka, which buffers messages and decouples the producer from the consumer
- Message brokers needs to scale horizontally just like the applications that use them, so their implementations are distributed
-
There are many tradeoffs involved with message brokers:
- Ordering of messages (insertion vs. consumption)
- Delivery guarantees, e.g. at-most-once or at-least-once
- Message durability guarantees
- Latency
- Messaging standards supported, e.g. AMQP
- Support for competing consumer instances
- Broker limits, e.g. the maximum supported size of messages
Exactly-Once Processing#
-
A consumer instance has to delete a message from the channel once it’s done processing it so that another instance won’t read it
- If the consumer deletes the message before processing it, it could crash in between, causing the message to be lost forever
- If the consumer deletes the message only after processing it, it could crash in between, causing the same message to be read again later on
-
So, there is no such thing is exactly-once message delivery
- The best a consumer can do is simulate exactly-once message delivery by requiring messages to be idempotent and deleting them from the channel only after they have been processed
Failures#
- To guard against a specific message consistently failing and being retried, we need to limit the maximum number of times the same message can be read from the channel
- To do this, the broker can stamp each message with a counter that keeps track of the number of times the message has been delivered to a consumer
- When the maximum retry limit is reached, the consumer can remove the message from the channel after writing it to a dead letter channel – this way, these messages are not lost forever but don’t clog up the main channel
Backlogs#
-
When the consumer can’t keep up with the producer, a backlog builds up, which could be caused by several reasons:
- More producer instances come online, and/or their throughput increases
- The consumer’s performance has degraded
- The consumer fails to process a fraction of the messages, meaning they stay in the channel for some time
-
To detect backlogs, we monitor the average time a message waits in the channel to be read for the first time
Fault Isolation#
- A single producer instance that emits “poisonous” messages that repeatedly fail to be processed can degrade the consumer and potentially create a backlog
- Therefore, it’s important to find ways to deal with poisonous messages
Part IV: Resiliency#
Chapter 24: Common Failure Causes#
Hardware Faults#
-
Any physical part of a machine can fail: HDDs, memory modules, power supplies, motherboards, SSDs, NICs, CPUs
- Entire data centers can go down because of power cuts or natural disasters
-
In some cases, hardware faults can cause data corruption as well
Configuration Changes#
- Misconfigurations or configuration changes to features that no longer work as expected can cause catastrophic failures
Single Points of Failure#
- A single point of failure (SPOF) is a component whose failure brings the entire system down with it
Network Faults#
- There could be many reasons that clients are not receiving prompt responses from a server:
- The server has crashed and is unavailable
- The network could be losing some packets, causing retransmissions and delays
Resource Leaks#
- Resource leaks are a common cause of slow processes, which can look just like processes that aren’t running at all
Load Pressure#
- Surges in load can cause a system to become overloaded with an opportunity to scale out, for example:
- Requests might have a seasonality (spikes at certain times of the day)
- Some requests might be more expensive than others
- Some requests are malicious, e.g. DDoS attacks
Cascading Failures#
- Faults have the potential to spread virally and cascade from one process to another until the whole system begins to fail
- This is more likely when components depend on each other
Chapter 25: Redundancy#
-
Redundancy, the replication of functionality or state, is the first line of defense against failures
-
When does redundancy actually help?
- The complexity added shouldn’t cost more availability than it adds
- The system must reliably detect which of the redundant components are healthy and which are unhealthy
- The system must be able to run in degraded mode
- The system must be able to return to fully redundant mode
-
For example, a load balancer increases a system’s complexity but provided significant benefits in terms of scalability and availability
- It can detect which nodes are healthy and which aren’t, via health checks, to take the faulty ones out of the pool
- When faulty servers are removed from the pool, we must ensure the remaining servers have enough capacity left to handle the increase in load (and also add new servers to replace the ones that have been lost)
-
Redundancy is only helpful when the redundant nodes can’t fail for the same reason at the same time, i.e. when failures are not correlated
Chapter 26: Fault Isolation#
-
We can partition the application’s stack by user so that the requests of a specific user can only ever affect the partition it was assigned to
- That way, even if a user is degrading a partition, the issue is isolated from the rest of the system
-
For example, let’s say we have 6 instances of a service behind a load balancer, divided into 3 partitions
- In this case, a noisy or poisonous user can only ever impact 33% of users
- As the number of partitions increases, the blast radius decreases further
-
The use of partitions for fault isolation is called the bulkhead pattern
Shuffle Sharding#
-
The problem with partitioning is that users who are unlucky enough to land on a degraded partition are impacted as well
-
With shuffle sharding, we can introduce virtual partitions composed of random (but permanent) subsets of service instances
- This makes it much more unlikely for two users to be allocated to the same partition as each other
-
The caveat is that virtual partitions partially overlap, unlike physical partitions
- But by combining shuffle sharding with a load balancer that removes faulty instances and clients that retry failed requests, we can build a system with much better fault isolation than one with physical partitions alone
Cellular Architecture#
-
We can take it up a notch and partition the entire application stack, including its dependencies (load balancers, compute services, storage services, etc.) by user into cells
- Each cell is completely independent of others, and a gateway service is responsible for routing requests to the right cells
-
A benefit of cellular architectures is that we set a maximum size for a cell, so when the system needs to scale out, a new cell is added rather than scaling out existing ones
Chapter 27: Downstream Resiliency#
Timeout#
- When a network call is made, it’s best practice to configure a timeout to fail the call if no response is received
Retry#
- When a client’s request fails or times out, retrying after some backoff time is a common choice
- If the downstream service is overwhelmed, retrying immediately will only worsen matters
- Therefore, retrying needs to be slowed down with increasingly longer delays between the individual retries until either a maximum number of retries is reached or enough time has passed since the initial request
Exponential Backoff#
-
We can use exponential backoff with a cap to set the delay between retries
- For example, if the cap is set to 8 seconds, and the initial backoff duration is 2 seconds, then the first retry delay is 2 seconds, the second is 4 seconds, the third is 8 seconds, and any further delays will be capped to 8 seconds
-
When the downstream service is temporarily degraded, clients will be retrying simultaneously, causing further load spikes that cause further degradation
- To avoid this herding behavior, we can introduce random jitter into the delay calculation
- This spreads retries out over time, smoothing out the load to the downstream service
-
If the error causing the failure of a network call is not short-lived, e.g. because the process is not authorized to access the remote endpoint, it makes no sense to retry the request since it will just fail again
Retry Amplification#
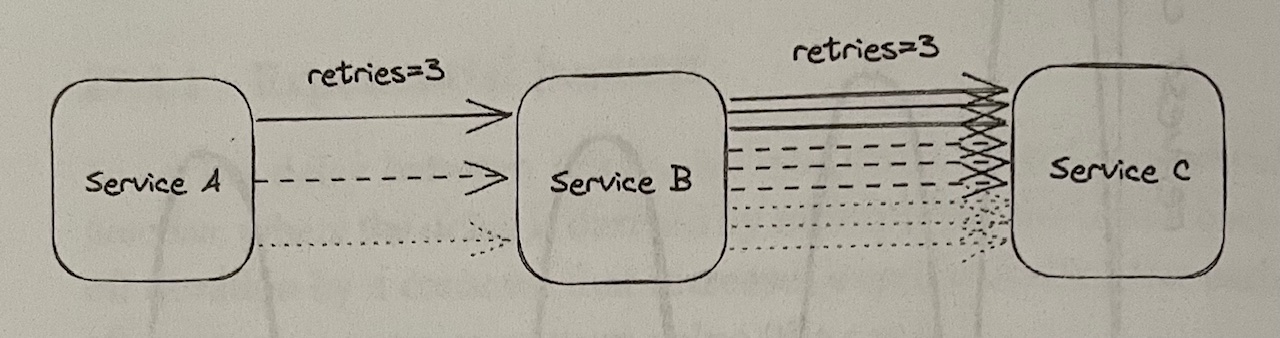
- Let’s say a user’s request requires going through a chain of three services: the user’s client calls service A, which calls service B, which calls service C
- If the call from B to C fails and B retries, A will perceive a longer execution time for its request, making it more likely for it to time out and retry
- Having retries at multiple levels of the dependency chain can amplify the total number of retries - the deeper a service is in the chain, the higher the load it will be exposed to due to retry amplification
Circuit Breaker#
- The goal of a circuit breaker is to detect long-term degradations of downstream dependencies and stop new requests from being sent downstream in the first place
- Retries are helpful when the expectation is that the next call will succeed, while circuit breakers are helpful with the expectation is that the next call will fail
Chapter 28: Upstream Resiliency#
Load Shedding#
-
When a server operates at capacity, it should reject excess requests so that it can dedicate its resources to the requests it’s already processing
-
If different requests have different priorities, the server could reject only low-priority ones
Load Leveling#
-
By introducing a messaging channel between the clients and the service, the load directed to the service is decoupled from its capacity, allowing it to process requests at its own pace
-
However, if the service doesn’t catch up eventually, a large backlog will build up
Rate-Limiting#
-
Rate-limiting, or throttling, is a mechanism that rejects a request when a specific quota is exceeded
-
A service can have multiple quotas, e.g. for the number of requests or bytes received within a time interval
- Quotas are typically applied to specific users, API keys, or IP addresses
- Because there is a global state involved, some form of coordination is required
Single-Process Implementation#
- We can divide time into buckets of fixed duration, and keep track of how many requests have been seen within each bucket
- We can then use a sliding window that moves across the buckets in real time, keeping track of the number of requests within it
- The sliding window represents the interval of time used to decide whether to rate-limit or not
Distributed Implementation#
-
When more than one process accepts requests, the local state is no longer good enough, since the quota needs to be enforced on the total number of requests per API key across all service instances
- This requires a shared data store to keep track of the number of requests seen
-
When a new request comes in, the process receiving it could fetch the current bucket, update it, and write it back to the data store
- To avoid any race conditions, the fetch, update, and write operations need to be packaged into a single transaction
- However, transactions are slow, and executing one per request would be very expensive
-
Instead of using transactions, we can use a single atomic get-and-increment or compare-and-swap operation
- Instead of updating the data store on each request, the process can batch bucket updates in memory for some time and flush them asynchronously to the data store
- This reduces the shared state’s accuracy, but it’s a good tradeoff since it reduces the load on the data store
-
If the data store is down, it’s safest to keep serving requests based on the last state read from the store, rather than temporarily rejecting requests just because the data store used for rate-limiting is not reachable
Constant Work#
-
When overload, configuration changes, or faults force an application to behave differently from usual, we say the application has a multi-modal behavior
- We should strive to minimize the number of modes
-
Ideally, the worst- and average-case behavior shouldn’t differ
- With the constant work pattern, the system should perform the same amount of work under high load as under average load
Part V: Maintainability#
Chapter 29: Testing#
-
Tests not only catch bugs in intended functionality early on, they also act as up-to-date documentation for the application
- However, testing is not a silver bullet because it’s impossible to predict all the states a complex distributed application can get into
-
A unit test validates the behavior of a small part of the codebase, like an individual class. A unit test should:
- Use only the public interfaces of the system under test (SUT)
- Test for state changes in the SUT (not predetermined sequences of actions)
- Test for behaviors, i.e. how the SUT handles a given input when it’s in a specific state
-
An integration test has a larger scope than a unit test, since it verifies that a service can interact with an external dependency as expected
-
An end-to-end test validates behavior that spans multiple services in the system, like a user-facing scenario
- Because of their scope, they can be slow, more prone to intermittent failures, and painful/expensive to maintain
-
Intermittently failing tests are nearly as bad as no tests at all, since developers stop trusting them and eventually ignore their failures
- When possible, it’s preferable to have tests with smaller scope, as they tend to be more reliable, faster, and cheaper
-
The size of a test reflects how much computing resources it needs to run, like the number of nodes
- A small test runs in a single process and doesn’t perform any blocking calls or I/O
- An intermediate test runs on a single node and performs local I/O, like reads from disk or network calls to localhost
- A large test requires multiple nodes to run, introducing even more non-determinism and longer delays
Chapter 30: Continuous Delivery and Deployment#
-
The whole release process, including rollbacks, can be automated with a continuous delivery and deployment (CD) pipeline
-
The provisioning of infrastructure should be automated via Infrastructure-as-Code tools like Terraform
-
Since rolling forward is much riskier than rolling back, we should aim to have all changes be backward-compatible as a rule of thumb
-
Suppose the messaging schema between a producer and a consumer service needs to change in a backward-incompatible way. In this case, the change is broken down into three smaller changes that can individually be rolled back safely:
- Prepare: the consumer is modified to support both the new and old messaging formats
- Activate: the producer is modified to write the messages in the new format
- Cleanup: the consumer stops supporting the old messaging format altogether, now only using the new one
Chapter 31: Monitoring#
-
A metric is a time series of raw measurements (samples) of resource usage (e.g. CPU utilization) or behavior (e.g. number of requests that failed), where each sample is represented by a floating-point number and a timestamp
- A metric can also be tagged with a set of key-value pairs, making it easier to slice and dice the data
-
At the very least, a service should emit metrics about its load (e.g. request throughput), its internal state (e.g. in-memory cache size), and its dependencies’ availability and performance (e.g. data store response time)
-
Events are costly to aggregate at query time, but we can potentially reduce costs by pre-aggregating time-series samples over fixed time periods (e.g. 1 minute, 5 minutes, 1 hour, etc.) and represented with summary statistics such as the sum, average, or percentiles
- We can take this approach one step further and also reduce ingestion costs by having the local telemetry agents pre-aggregate metrics client-side
-
Some common service-level indicators (SLIs) for services are response time (the fraction of requests that are completed faster than a given threshold) and availability (the proportion of time the service was usable, defined as the number of successful requests over the total number of requests)
-
Alerting is the part of a monitoring system that triggers an action when a specific condition happens, like a metric crossing a threshold
- For an alert to be useful, it has to be actionable
Chapter 32: Observability#
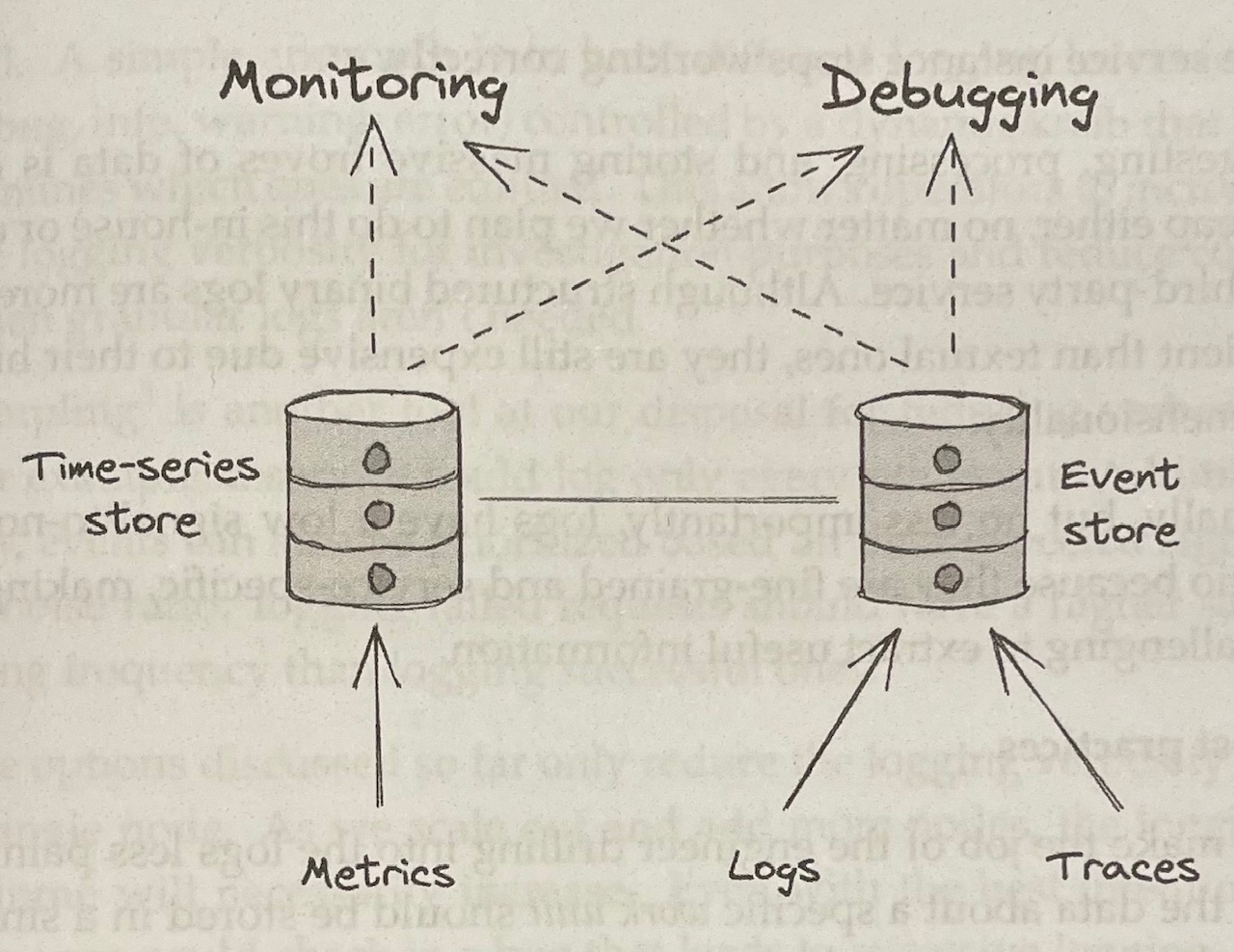
- Good observability requires telemetry sources like metrics, event logs, and traces
- Metrics are stored in time-series data stores that have high throughput but struggle with high dimensionality
- Conversely, event logs and traces end up in stores that can handle high-dimensional data but struggle with high throughput
- Metrics are mainly used for monitoring, while event logs and traces are mainly for debugging
Logs#
-
A log is an immutable list of time-stamped events that happened over time
- An event can be free-form text, JSON, binary (e.g. Protobuf), etc.
- When structured, an event is typically represented with a bag of key-value pairs
-
Logs are especially helpful for debugging purposes, when you have something you know you want to look for/investigate
- Logging libraries can add overhead to our services if misused or overused
- Ingesting, processing, and storing this data is not cheap, especially with high-dimensional structured data
-
To make drilling into logs easier, all data regarding a single work unit (a request or message pulled from a queue) should be stored in a single event
Traces#
- Tracing captures the entire lifespan of a request as it propagates throughout the services of a distributed system
- A trace is a list of casually-related spans that represent the execution flow of a request in a system
- A span represents an interval of time that maps to a logical operation or work unit and contains a bag of key-value pairs
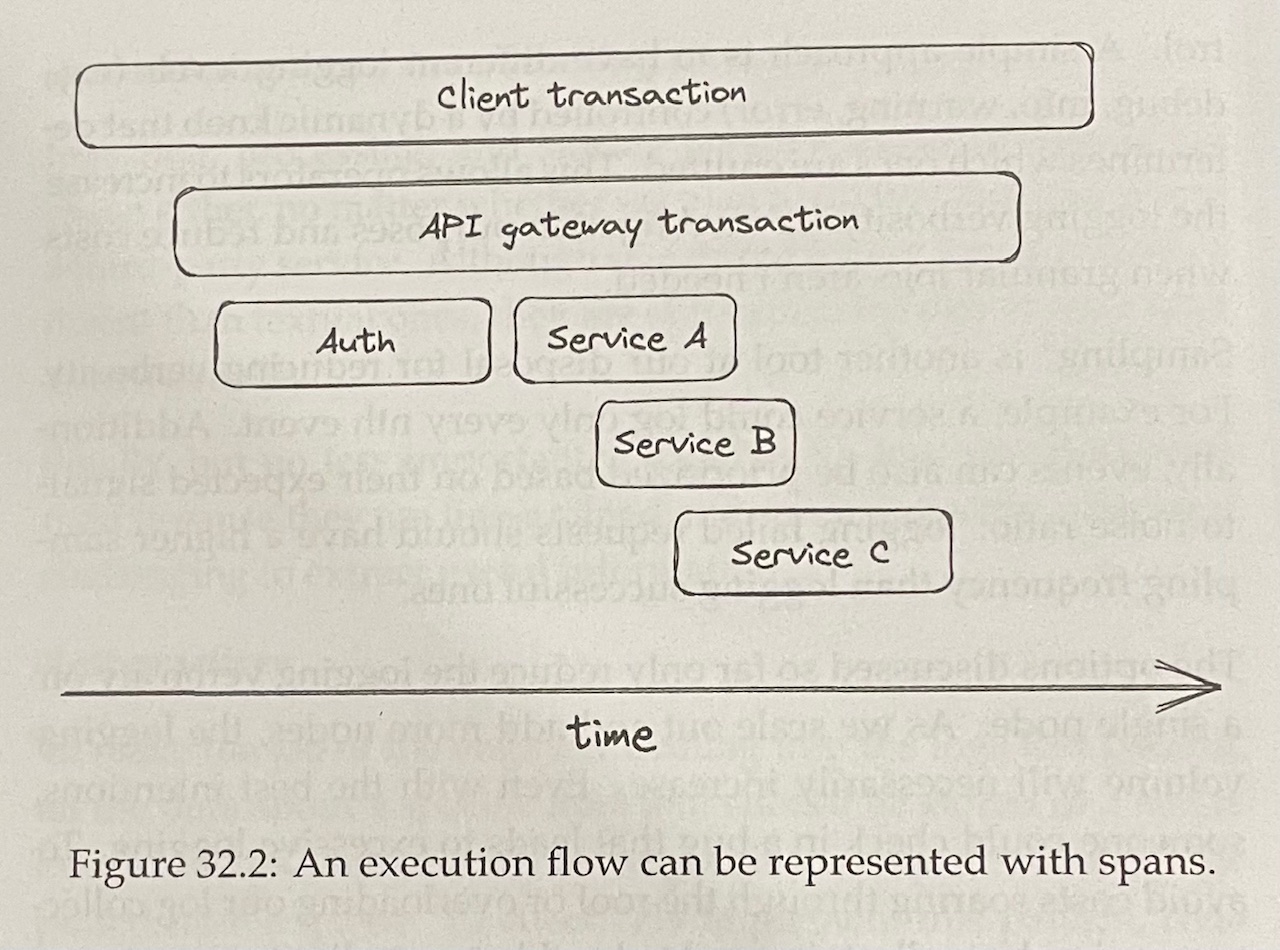
- Each stage above is represented with a span - an event containing the trace ID
- When a span ends, it’s emitted to a collector service, which assembles it into a trace by stitching it together with the other spans belonging to the same trace
Chapter 33: Manageability#
-
To decouple an application from its configuration, the configuration can be persisted in a dedicated store
- At deployment time, the CD pipeline reads the configuration from the store and passes it to the application through environment variables
-
Once it’s possible to change configuration settings dynamically, new features can be released with settings to toggle (enable/disable) them, i.e. feature flags
- This allows a build to be released with a new feature disabled at first
- Later, the feature can be enabled for a fraction of application instances (or users) to build up confidence that it’s working as intended before it’s fully rolled out
- The same mechanism can be used to perform A/B tests