Git Internals: Object Model, Packfiles, & Index Files
I recently wrote an extremely basic implementation of Git in Golang inspired by the CodeCrafters challenge. My goal was to gain a better understanding of how Git (and systems like it with custom protocols) works internally. While this project has no practical value (why would anyone want to write their own Git for any reason other than learning?), understanding Git’s internals can be valuable for:
- Debugging complex Git issues
- Understanding how version control systems work at a fundamental level
- Learning about distributed systems and data structures
- Appreciating the engineering decisions behind Git’s design
My implementation supports just enough commands to allow for initializing/cloning repositories, making commits, pushing and pulling, and creating/checking out branches.
While working on this project, I found the official Git documentation on the object model, packfile, and index file formats to be severely lacking. So, I decided to document some of the implementation details that I found most fiddly.
Table of Contents
The .git/ Directory#
The .git/ directory is home base for any Git repository; it’s where Git stores all the information it needs about the repo’s configuration, files, and states over multiple versions (commits). This is a great intro to the basic structure of .git/.
Object Model#
The Git object database, managed in .git/objects/, is a simple collection of text files. Each object receives a SHA-1 hash based on its contents (including the header), and can be retrieved from the database using that hash. The complete content of each object file is compressed with zlib before being written to the local disk.
For performance reasons, Git uses a two-level directory structure to store objects. The first two characters of the hash are used as the directory name, and the remaining characters form the filename. For example, an object with hash 6769dd60bdf536a83c9353272157893043e9f7d0 would be stored at .git/objects/67/69dd60bdf536a83c9353272157893043e9f7d0.
Note that there are no newline characters in any of these object files unless explicitly specified with \n.
Blobs#
Each blob object represents a file in the repository. The literal string “blob” in the header indicates the object type. The header also contains <size>, indicating the number of bytes in <content>. Separating the header and the content is the null byte \0. Finally, <content> for a blob is just the content of the actual file in the repository.
blob <size>\0
<content>
For example, let’s say we have a file file.txt with content “Hello world!”. The blob representing this file will be structured as:
blob 12\0
Hello world!
The SHA-1 hash of the full content of this object file is 6769dd60bdf536a83c9353272157893043e9f7d0, so this is the hash associated with this blob.
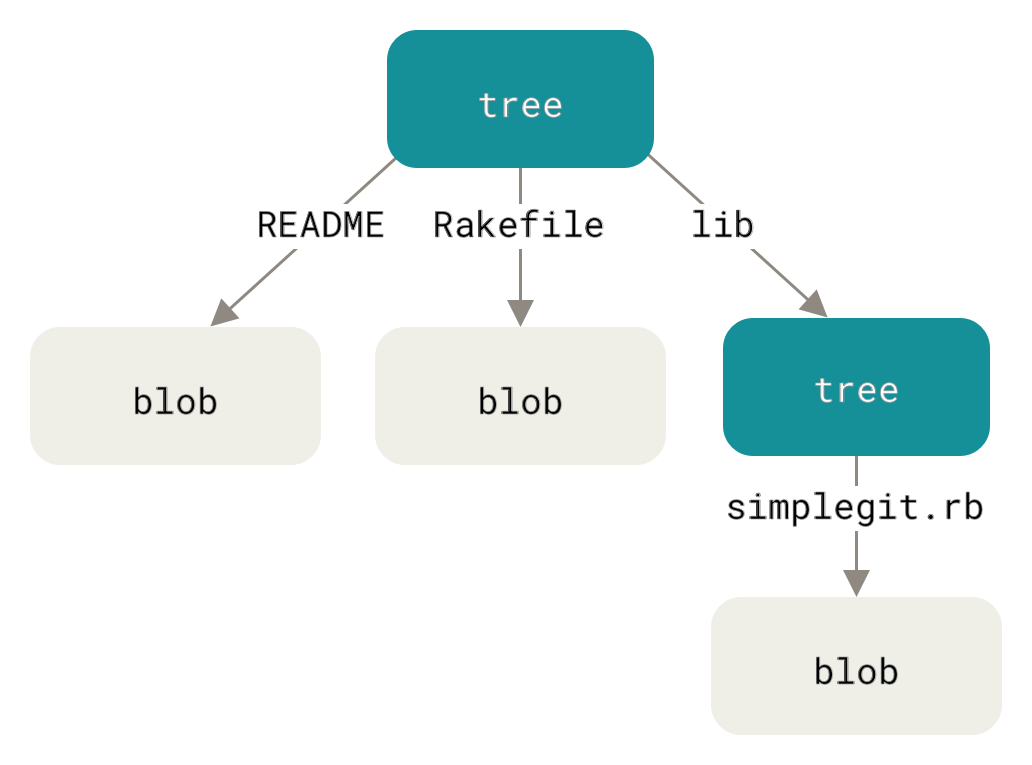
Trees#
Next, a tree object represents the structure of a directory within the repository at a given point in time. Each tree has some number of entries, which can themselves be either blobs (files) or trees (subdirectories).
<size> is again the number of bytes in <content> (everything in the object file following the null byte that terminates the header). <mode> and <name> are the mode and name of the corresponding file/directory entry in this tree. The mode/name and hash for each entry are separated by a null byte. Entries in a tree are sorted in increasing lexicographic order by their name.
The mode numbers have specific meanings:
100644: Regular file100755: Executable file040000: Directory120000: Symbolic link
tree <size>\0
<mode> <name>\0<entry_hash>
<mode> <name>\0<entry_hash>
For example, let’s say we have the following directory structure:
/dir-1
/dir-2
file-1.txt (28bf5b1fb91bbd487987d6d3d517a727b9779f14)
file-2.txt (4419d52b7a5c674ead13bb5c914849d2fb21c74b)
another-file.txt (8e2b5c59ac0d64f415ddafc1f21016be423a9543)
The tree object for dir-2/ will be structured as:
tree 38\0
100644 file-1.txt\028bf5b1fb91bbd487987d6d3d517a727b9779f14
The tree object for dir-1/ will be structured as:
tree 114\0
100644 another-file.txt\08e2b5c59ac0d64f415ddafc1f21016be423a9543
040000 dir-2\0ee3b00787ca139eb7ca543f2ae425c434b55efa4
100644 file-2.txt\04419d52b7a5c674ead13bb5c914849d2fb21c74b
Commits#
Finally, a commit object stores the state (directory & file structure) of the repository at one point in time. It consists of a tree along with any metadata describing the commit.
<tree_hash> is the hash of the tree object tied to this commit. <parents> is an optional list of parent commits. There is a blank line between the author/committer information and the (optional) commit message. See here for more information.
commit <size>\0
tree <tree_hash>\n
<parents>\n
author {author_name} <{author_email}> {author_date_seconds} {author_date_timezone}\n
committer {committer_name} <{committer_email}> {committer_date_seconds} {committer_date_timezone}\n
<commit_message>
For example, here’s what a commit object in my test repository looks like (newline characters omitted):
commit 245\0
tree 4bc3582b4de5d27f7d3056c7c451e9f5954b4165
parent 04ff4bf3866ee842d9eab61fc064839117053b04
author Shashank Jarmale <[email protected]> 1744579894 -0400
committer Shashank Jarmale <[email protected]> 1744579894 -0400
change
Packfile Format#
The packfile format is how Git repository data is stored in bulk. A packfile consists of three sections:
- The packfile header
- The encoded versions of objects contained in the packfile
- A checksum of the packfile, for verification
Packfile Header#
<PACK><VERSION_NUM><NUM_OBJECTS>
<PACK>: 4-byte signature, which is 'PACK'
<VERSION_NUM>: 4-byte version number (network byte order), version 2 and 3 currently supported
<NUM_OBJECTS>: 4-byte number of objects contained in the packfile (network byte order)
Packfile-Encoded Object#
A single (non-delta) object in a packfile is encoded as:
<OBJ_HEADER><OBJ_DATA>
<OBJ_HEADER>: n bytes indicating the object type and length, where bits 6-4 of the first byte indicate the object type and bits 3-0 of the first byte along with the remaining (n - 1) bytes indicate the length of the object data when decompressed
<OBJ_DATA>: the object data (content) compressed with zlib
The possible packfile object types are:
- 1: commit
- 2: tree
- 3: blob
- 4: tag
- 5: none (reserved for future expansion)
- 6: ofs delta
- 7: ref delta
With regards to the object length in <OBJ_HEADER>, see here.
Packfile Checksum#
The final 20 bytes of the packfile contain a SHA1 checksum of all the data that came before in the packfile.
Index File Format#
The Git index file (also called the staging area) is a middle ground between the active working directory and the repository object database. Whatever files are stored in the index file are staged for the next commit. The format of the index file is described here.
The index file consists of four sections:
- The index file header
- Some number of index entries (sorted in ascending order on the name field)
- Extensions
- Checksum
Index File Header#
<DIRC><VERSION_NUM><INDEX_ENTRIES_NUM>
<DIRC>: 4-byte signature, which is 'DIRC'
<VERSION_NUM>: 4-byte version number (network byte order), versions 2, 3, and 4 currently supported
<INDEX_ENTRIES_NUM>: 4-byte number of index entries (network byte order)
Index File Checksum#
The final 20 bytes of the index file contain a SHA1 checksum of all the data that came before in the index file.